 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaRE: A Cross-Domain Recommender System with Domain-aware Feature Extraction and Review Encoder
Oct 25, 2021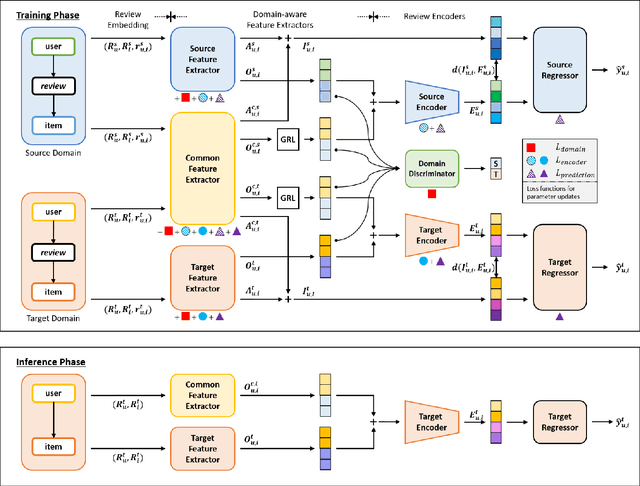

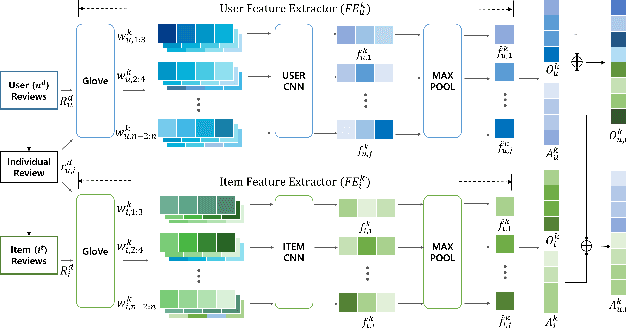
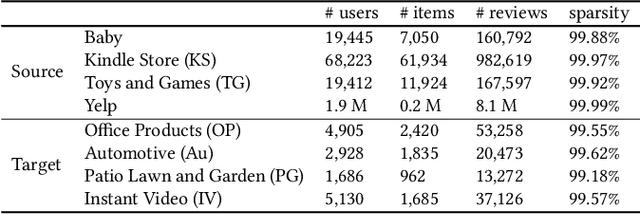
Recent advent in recommender systems, especially text-aided methods and CDR (Cross-Domain Recommendation) leads to promising results in solving data-sparsity and cold-start problems. Despite such progress, prior algorithms either require user overlapping or ignore domain-aware feature extraction. In addition, text-aided methods exceedingly emphasize aggregated documents and fail to capture the specifics embedded in individual reviews. To overcome such limitations, we propose a novel method, named DaRE (Domainaware Feature Extraction and Review Encoder), a comprehensive solution that consists of three key components; text-based representation learning, domain-aware feature extraction, and a review encoder. DaRE debilitate noises by separating domain-invariant features from domain-specific features through selective adversarial training. DaRE extracts features from aggregated documents, and the review encoder fine-tunes the representations by aligning them with the features extracted from individual reviews. Experiments on four real-world datasets show the superiority of DaRE over state-ofthe-art single-domain and cross-domain methodologies, achieving 9.2 % and 3.6 % improvements, respectively. We upload our implementations (https://anonymous.4open.science/r/DaRE-9CC9/) for a reproducibility