 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBandit Learning in General Open Multi-agent Systems
May 07, 2026Recent developments in digital platforms have highlighted the prevalence of open systems, where agents can arrive and depart over time. While bandit learning in open systems has recently received initial attention, existing work imposes structural assumptions that are frequently violated in practice. A learning paradigm for general open systems creates fresh challenges: newly arriving agents induce endogenous non-stationarity; agent patterns determine how quickly information accumulates; and new agents make regret scale further with the time horizon. To this end, we formulate a unified open-system bandit problem with general dynamics, including heterogeneous rewards and general agent patterns. We introduce new concepts to capture the inherent complexities: the \emph{pre-training degree} of new agents quantifies how much information an agent carries upon entry, \emph{stability} measures the impact of new agents on the system, and \emph{global dynamic regret} compares the cumulative expected reward of all active agents with that of the varying optimal arms. We develop certified global-UCB learning methodologies with provable guarantees. Our regret bounds reveal that entry uncertainty enters linearly via the pre-training degree, while in stable regimes, regret is governed by the time needed to identify a persistent optimal arm, as well as by the agent patterns. We further show that these dependencies are tight via lower bounds in hard instances.
Are Stochastic Multi-objective Bandits Harder than Single-objective Bandits?
Apr 08, 2026Multi-objective bandits have attracted increasing attention because of their broad applicability and mathematical elegance, where the reward of each arm is a multi-dimensional vector rather than a scalar. This naturally introduces Pareto order relations and Pareto regret. A long-standing question in this area is whether performance is fundamentally harder to optimize because of this added complexity. A recent surprising result shows that, in the adversarial setting, Pareto regret is no larger than classical regret; however, in the stochastic setting, where the regret notion is different, the picture remains unclear. In fact, existing work suggests that Pareto regret in the stochastic case increases with the dimensionality. This controversial yet subtle phenomenon motivates our central question: \emph{are multi-objective bandits actually harder than single-objective ones?} We answer this question in full by showing that, in the stochastic setting, Pareto regret is in fact governed by the maximum sub-optimality gap \(g^\dagger\), and hence by the minimum marginal regret of order \(Ω(\frac{K\log T}{g^\dagger})\). We further develop a new algorithm that achieves Pareto regret of order \(O(\frac{K\log T}{g^\dagger})\), and is therefore optimal. The algorithm leverages a nested two-layer uncertainty quantification over both arms and objectives through upper and lower confidence bound estimators. It combines a top-two racing strategy for arm selection with an uncertainty-greedy rule for dimension selection. Together, these components balance exploration and exploitation across the two layers. We also conduct comprehensive numerical experiments to validate the proposed algorithm, showing the desired regret guarantee and significant gains over benchmark methods.
Bandit Learning in Matching Markets with Interviews
Feb 12, 2026Two-sided matching markets rely on preferences from both sides, yet it is often impractical to evaluate preferences. Participants, therefore, conduct a limited number of interviews, which provide early, noisy impressions and shape final decisions. We study bandit learning in matching markets with interviews, modeling interviews as \textit{low-cost hints} that reveal partial preference information to both sides. Our framework departs from existing work by allowing firm-side uncertainty: firms, like agents, may be unsure of their own preferences and can make early hiring mistakes by hiring less preferred agents. To handle this, we extend the firm's action space to allow \emph{strategic deferral} (choosing not to hire in a round), enabling recovery from suboptimal hires and supporting decentralized learning without coordination. We design novel algorithms for (i) a centralized setting with an omniscient interview allocator and (ii) decentralized settings with two types of firm-side feedback. Across all settings, our algorithms achieve time-independent regret, a substantial improvement over the $O(\log T)$ regret bounds known for learning stable matchings without interviews. Also, under mild structured markets, decentralized performance matches the centralized counterpart up to polynomial factors in the number of agents and firms.
Distributed Multi-Agent Bandits Over Erdős-Rényi Random Networks
Oct 26, 2025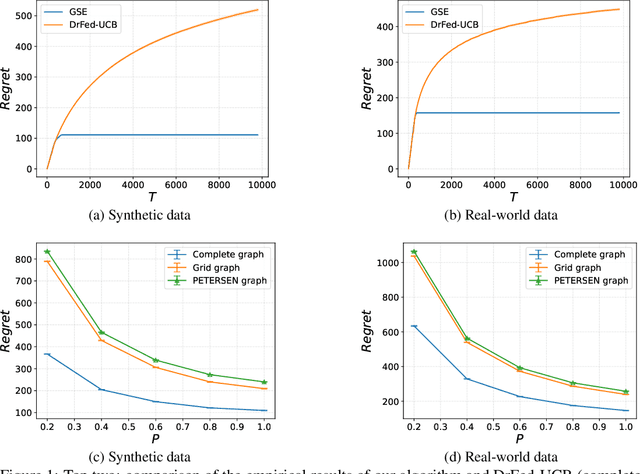

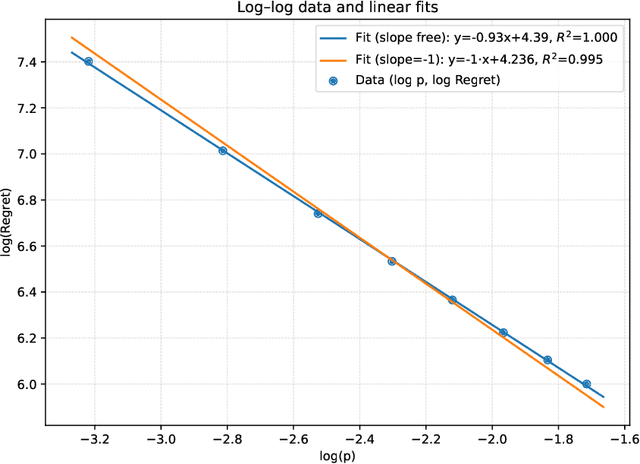
We study the distributed multi-agent multi-armed bandit problem with heterogeneous rewards over random communication graphs. Uniquely, at each time step $t$ agents communicate over a time-varying random graph $G_t$ generated by applying the Erd\H{o}s-R\'enyi model to a fixed connected base graph $G$ (for classical Erd\H{o}s-R\'enyi graphs, $G$ is a complete graph), where each potential edge in $G$ is randomly and independently present with the link probability $p$. Notably, the resulting random graph is not necessarily connected at each time step. Each agent's arm rewards follow time-invariant distributions, and the reward distribution for the same arm may differ across agents. The goal is to minimize the cumulative expected regret relative to the global mean reward of each arm, defined as the average of that arm's mean rewards across all agents. To this end, we propose a fully distributed algorithm that integrates the arm elimination strategy with the random gossip algorithm. We theoretically show that the regret upper bound is of order $\log T$ and is highly interpretable, where $T$ is the time horizon. It includes the optimal centralized regret $O\left(\sum_{k: \Delta_k>0} \frac{\log T}{\Delta_k}\right)$ and an additional term $O\left(\frac{N^2 \log T}{p \lambda_{N-1}(Lap(G))} + \frac{KN^2 \log T}{p}\right)$ where $N$ and $K$ denote the total number of agents and arms, respectively. This term reflects the impact of $G$'s algebraic connectivity $\lambda_{N-1}(Lap(G))$ and the link probability $p$, and thus highlights a fundamental trade-off between communication efficiency and regret. As a by-product, we show a nearly optimal regret lower bound. Finally, our numerical experiments not only show the superiority of our algorithm over existing benchmarks, but also validate the theoretical regret scaling with problem complexity.
Heterogeneous Multi-agent Multi-armed Bandits on Stochastic Block Models
Feb 11, 2025
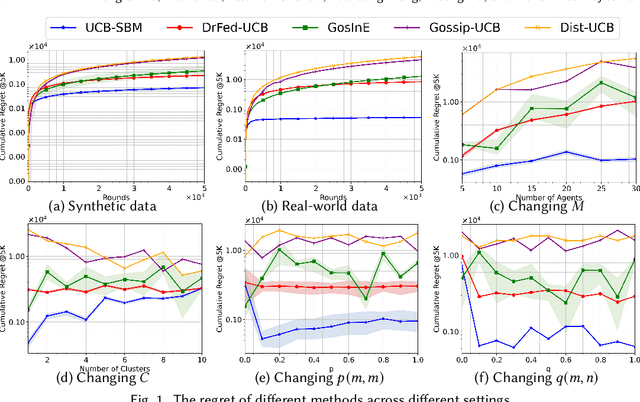
We study a novel heterogeneous multi-agent multi-armed bandit problem with a cluster structure induced by stochastic block models, influencing not only graph topology, but also reward heterogeneity. Specifically, agents are distributed on random graphs based on stochastic block models - a generalized Erdos-Renyi model with heterogeneous edge probabilities: agents are grouped into clusters (known or unknown); edge probabilities for agents within the same cluster differ from those across clusters. In addition, the cluster structure in stochastic block model also determines our heterogeneous rewards. Rewards distributions of the same arm vary across agents in different clusters but remain consistent within a cluster, unifying homogeneous and heterogeneous settings and varying degree of heterogeneity, and rewards are independent samples from these distributions. The objective is to minimize system-wide regret across all agents. To address this, we propose a novel algorithm applicable to both known and unknown cluster settings. The algorithm combines an averaging-based consensus approach with a newly introduced information aggregation and weighting technique, resulting in a UCB-type strategy. It accounts for graph randomness, leverages both intra-cluster (homogeneous) and inter-cluster (heterogeneous) information from rewards and graphs, and incorporates cluster detection for unknown cluster settings. We derive optimal instance-dependent regret upper bounds of order $\log{T}$ under sub-Gaussian rewards. Importantly, our regret bounds capture the degree of heterogeneity in the system (an additional layer of complexity), exhibit smaller constants, scale better for large systems, and impose significantly relaxed assumptions on edge probabilities. In contrast, prior works have not accounted for this refined problem complexity, rely on more stringent assumptions, and exhibit limited scalability.
Multi-agent Multi-armed Bandit with Fully Heavy-tailed Dynamics
Jan 31, 2025We study decentralized multi-agent multi-armed bandits in fully heavy-tailed settings, where clients communicate over sparse random graphs with heavy-tailed degree distributions and observe heavy-tailed (homogeneous or heterogeneous) reward distributions with potentially infinite variance. The objective is to maximize system performance by pulling the globally optimal arm with the highest global reward mean across all clients. We are the first to address such fully heavy-tailed scenarios, which capture the dynamics and challenges in communication and inference among multiple clients in real-world systems. In homogeneous settings, our algorithmic framework exploits hub-like structures unique to heavy-tailed graphs, allowing clients to aggregate rewards and reduce noises via hub estimators when constructing UCB indices; under $M$ clients and degree distributions with power-law index $\alpha > 1$, our algorithm attains a regret bound (almost) of order $O(M^{1 -\frac{1}{\alpha}} \log{T})$. Under heterogeneous rewards, clients synchronize by communicating with neighbors, aggregating exchanged estimators in UCB indices; With our newly established information delay bounds on sparse random graphs, we prove a regret bound of $O(M \log{T})$. Our results improve upon existing work, which only address time-invariant connected graphs, or light-tailed dynamics in dense graphs and rewards.
Decentralized Blockchain-based Robust Multi-agent Multi-armed Bandit
Feb 06, 2024
We study a robust multi-agent multi-armed bandit problem where multiple clients or participants are distributed on a fully decentralized blockchain, with the possibility of some being malicious. The rewards of arms are homogeneous among the clients, following time-invariant stochastic distributions that are revealed to the participants only when the system is secure enough. The system's objective is to efficiently ensure the cumulative rewards gained by the honest participants. To this end and to the best of our knowledge, we are the first to incorporate advanced techniques from blockchains, as well as novel mechanisms, into the system to design optimal strategies for honest participants. This allows various malicious behaviors and the maintenance of participant privacy. More specifically, we randomly select a pool of validators who have access to all participants, design a brand-new consensus mechanism based on digital signatures for these validators, invent a UCB-based strategy that requires less information from participants through secure multi-party computation, and design the chain-participant interaction and an incentive mechanism to encourage participants' participation. Notably, we are the first to prove the theoretical guarantee of the proposed algorithms by regret analyses in the context of optimality in blockchains. Unlike existing work that integrates blockchains with learning problems such as federated learning which mainly focuses on numerical optimality, we demonstrate that the regret of honest participants is upper bounded by $log{T}$. This is consistent with the multi-agent multi-armed bandit problem without malicious participants and the robust multi-agent multi-armed bandit problem with purely Byzantine attacks.
Regret Lower Bounds in Multi-agent Multi-armed Bandit
Aug 15, 2023Multi-armed Bandit motivates methods with provable upper bounds on regret and also the counterpart lower bounds have been extensively studied in this context. Recently, Multi-agent Multi-armed Bandit has gained significant traction in various domains, where individual clients face bandit problems in a distributed manner and the objective is the overall system performance, typically measured by regret. While efficient algorithms with regret upper bounds have emerged, limited attention has been given to the corresponding regret lower bounds, except for a recent lower bound for adversarial settings, which, however, has a gap with let known upper bounds. To this end, we herein provide the first comprehensive study on regret lower bounds across different settings and establish their tightness. Specifically, when the graphs exhibit good connectivity properties and the rewards are stochastically distributed, we demonstrate a lower bound of order $O(\log T)$ for instance-dependent bounds and $\sqrt{T}$ for mean-gap independent bounds which are tight. Assuming adversarial rewards, we establish a lower bound $O(T^{\frac{2}{3}})$ for connected graphs, thereby bridging the gap between the lower and upper bound in the prior work. We also show a linear regret lower bound when the graph is disconnected. While previous works have explored these settings with upper bounds, we provide a thorough study on tight lower bounds.
Decentralized Randomly Distributed Multi-agent Multi-armed Bandit with Heterogeneous Rewards
Jun 08, 2023
We study a decentralized multi-agent multi-armed bandit problem in which multiple clients are connected by time dependent random graphs provided by an environment. The reward distributions of each arm vary across clients and rewards are generated independently over time by an environment based on distributions that include both sub-exponential and sub-gaussian distributions. Each client pulls an arm and communicates with neighbors based on the graph provided by the environment. The goal is to minimize the overall regret of the entire system through collaborations. To this end, we introduce a novel algorithmic framework, which first provides robust simulation methods for generating random graphs using rapidly mixing Markov chains or the random graph model, and then combines an averaging-based consensus approach with a newly proposed weighting technique and the upper confidence bound to deliver a UCB-type solution. Our algorithms account for the randomness in the graphs, removing the conventional doubly stochasticity assumption, and only require the knowledge of the number of clients at initialization. We derive optimal instance-dependent regret upper bounds of order $\log{T}$ in both sub-gaussian and sub-exponential environments, and a nearly optimal mean-gap independent regret upper bound of order $\sqrt{T}\log T$ up to a $\log T$ factor. Importantly, our regret bounds hold with high probability and capture graph randomness, whereas prior works consider expected regret under assumptions and require more stringent reward distributions.
Pareto Regret Analyses in Multi-objective Multi-armed Bandit
Dec 01, 2022

We study Pareto optimality in multi-objective multi-armed bandit by providing a formulation of adversarial multi-objective multi-armed bandit and properly defining its Pareto regrets that can be generalized to stochastic settings as well. The regrets do not rely on any scalarization functions and reflect Pareto optimality compared to scalarized regrets. We also present new algorithms assuming both with and without prior information of the multi-objective multi-armed bandit setting. The algorithms are shown optimal in adversarial settings and nearly optimal in stochastic settings simultaneously by our established upper bounds and lower bounds on Pareto regrets. Moreover, the lower bound analyses show that the new regrets are consistent with the existing Pareto regret for stochastic settings and extend an adversarial attack mechanism from bandit to the multi-objective one.