Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegret Bounds and Reinforcement Learning Exploration of EXP-based Algorithms
Paper and Code

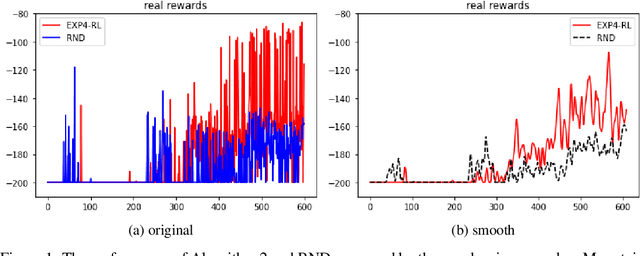
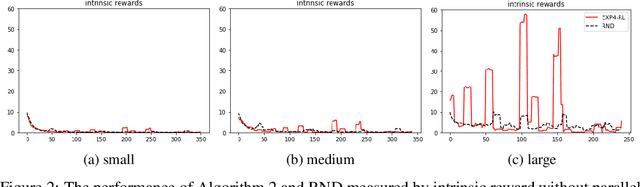
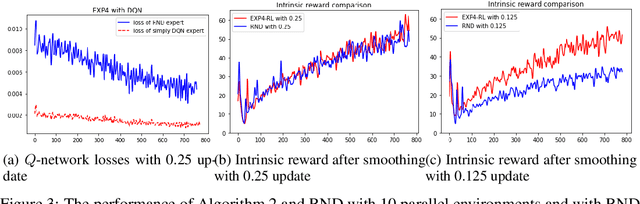
EXP-based algorithms are often used for exploration in multi-armed bandit. We revisit the EXP3.P algorithm and establish both the lower and upper bounds of regret in the Gaussian multi-armed bandit setting, as well as a more general distribution option. The analyses do not require bounded rewards compared to classical regret assumptions. We also extend EXP4 from multi-armed bandit to reinforcement learning to incentivize exploration by multiple agents. The resulting algorithm has been tested on hard-to-explore games and it shows an improvement on exploration compared to state-of-the-art.
* 20 pages, 8 figures
View paper on
 OpenReview
OpenReview