 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Topological Graph Reasoning for Language-Guided Pulmonary Screening
Apr 07, 2026Medical image segmentation driven by free-text clinical instructions is a critical frontier in computer-aided diagnosis. However, existing multimodal and foundation models struggle with the semantic ambiguity of clinical reports and fail to disambiguate complex anatomical overlaps in low-contrast scans. Furthermore, fully fine-tuning these massive architectures on limited medical datasets invariably leads to severe overfitting. To address these challenges, we propose a novel Semantic-Topological Graph Reasoning (STGR) framework for language-guided pulmonary screening. Our approach elegantly synergizes the reasoning capabilities of large language models (LLaMA-3-V) with the zero-shot delineation of vision foundation models (MedSAM). Specifically, we introduce a Text-to-Vision Intent Distillation (TVID) module to extract precise diagnostic guidance. To resolve anatomical ambiguity, we formulate mask selection as a dynamic graph reasoning problem, where candidate lesions are modeled as nodes and edges capture spatial and semantic affinities. To ensure deployment feasibility, we introduce a Selective Asymmetric Fine-Tuning (SAFT) strategy that updates less than 1% of the parameters. Rigorous 5-fold cross-validation on the LIDC-IDRI and LNDb datasets demonstrates that our framework establishes a new state-of-the-art. Notably, it achieves an 81.5% Dice Similarity Coefficient (DSC) on LIDC-IDRI, outperforming leading LLM-based tools like LISA by over 5%. Crucially, our SAFT strategy acts as a powerful regularizer, yielding exceptional cross-fold stability (0.6% DSC variance) and paving the way for robust, context-aware clinical deployment.
MERIT: Multilingual Expert-Reward Informed Tuning for Chinese-Centric Low-Resource Machine Translation
Apr 06, 2026Neural machine translation (NMT) from Chinese to low-resource Southeast Asian languages remains severely constrained by the extreme scarcity of clean parallel corpora and the pervasive noise in existing mined data. This chronic shortage not only impedes effective model training but also sustains a large performance gap with high-resource directions, leaving millions of speakers of languages such as Lao, Burmese, and Tagalog with persistently low-quality translation systems despite recent advances in large multilingual models. We introduce \textbf{M}ultilingual \textbf{E}xpert-\textbf{R}eward \textbf{I}nformed \textbf{T}uning (\textbf{MERIT}), a unified translation framework that transforms the traditional English-centric ALT benchmark into a Chinese-centric evaluation suite for five Southeast Asian low-resource languages (LRLs). Our framework combines language-specific token prefixing (LTP) with supervised fine-tuning (SFT) and a novel group relative policy optimization (GRPO) guided by the semantic alignment reward (SAR). These results confirm that, in LRL{\textrightarrow}Chinese translation, targeted data curation and reward-guided optimization dramatically outperform mere model scaling.
Beyond $\mathcal{O}(\sqrt{T})$ Regret: Decoupling Learning and Decision-making in Online Linear Programming
Jan 06, 2025



Online linear programming plays an important role in both revenue management and resource allocation, and recent research has focused on developing efficient first-order online learning algorithms. Despite the empirical success of first-order methods, they typically achieve a regret no better than $\mathcal{O} ( \sqrt{T} )$, which is suboptimal compared to the $\mathcal{O} (\log T)$ bound guaranteed by the state-of-the-art linear programming (LP)-based online algorithms. This paper establishes a general framework that improves upon the $\mathcal{O} ( \sqrt{T} )$ result when the LP dual problem exhibits certain error bound conditions. For the first time, we show that first-order learning algorithms achieve $o( \sqrt{T} )$ regret in the continuous support setting and $\mathcal{O} (\log T)$ regret in the finite support setting beyond the non-degeneracy assumption. Our results significantly improve the state-of-the-art regret results and provide new insights for sequential decision-making.
Decoupling Learning and Decision-Making: Breaking the $\mathcal{O}(\sqrt{T})$ Barrier in Online Resource Allocation with First-Order Methods
Feb 11, 2024



Online linear programming plays an important role in both revenue management and resource allocation, and recent research has focused on developing efficient first-order online learning algorithms. Despite the empirical success of first-order methods, they typically achieve a regret no better than $\mathcal{O}(\sqrt{T})$, which is suboptimal compared to the $\mathcal{O}(\log T)$ bound guaranteed by the state-of-the-art linear programming (LP)-based online algorithms. This paper establishes several important facts about online linear programming, which unveils the challenge for first-order-method-based online algorithms to achieve beyond $\mathcal{O}(\sqrt{T})$ regret. To address the challenge, we introduce a new algorithmic framework that decouples learning from decision-making. More importantly, for the first time, we show that first-order methods can attain regret $\mathcal{O}(T^{1/3})$ with this new framework. Lastly, we conduct numerical experiments to validate our theoretical findings.
A Homogenization Approach for Gradient-Dominated Stochastic Optimization
Aug 21, 2023



Gradient dominance property is a condition weaker than strong convexity, yet it sufficiently ensures global convergence for first-order methods even in non-convex optimization. This property finds application in various machine learning domains, including matrix decomposition, linear neural networks, and policy-based reinforcement learning (RL). In this paper, we study the stochastic homogeneous second-order descent method (SHSODM) for gradient-dominated optimization with $\alpha \in [1, 2]$ based on a recently proposed homogenization approach. Theoretically, we show that SHSODM achieves a sample complexity of $O(\epsilon^{-7/(2 \alpha) +1})$ for $\alpha \in [1, 3/2)$ and $\tilde{O}(\epsilon^{-2/\alpha})$ for $\alpha \in [3/2, 2]$. We further provide a SHSODM with a variance reduction technique enjoying an improved sample complexity of $O( \epsilon ^{-( 7-3\alpha ) /( 2\alpha )})$ for $\alpha \in [1,3/2)$. Our results match the state-of-the-art sample complexity bounds for stochastic gradient-dominated optimization without \emph{cubic regularization}. Since the homogenization approach only relies on solving extremal eigenvector problems instead of Newton-type systems, our methods gain the advantage of cheaper iterations and robustness in ill-conditioned problems. Numerical experiments on several RL tasks demonstrate the efficiency of SHSODM compared to other off-the-shelf methods.
NeuroExplainer: Fine-Grained Attention Decoding to Uncover Cortical Development Patterns of Preterm Infants
Jan 01, 2023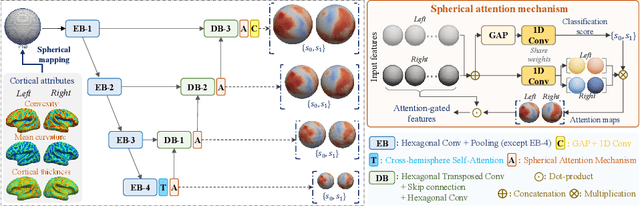
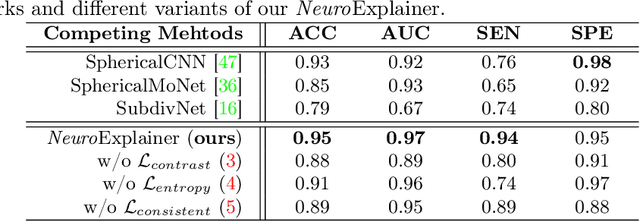
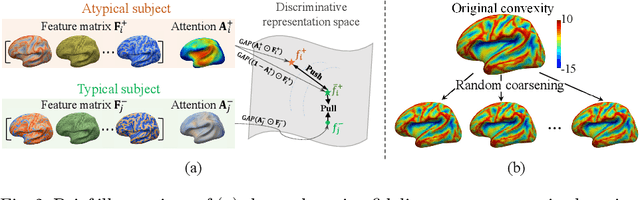
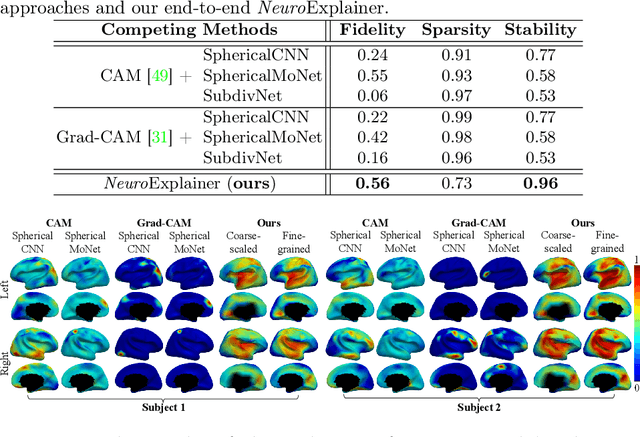
Deploying reliable deep learning techniques in interdisciplinary applications needs learned models to output accurate and ({even more importantly}) explainable predictions. Existing approaches typically explicate network outputs in a post-hoc fashion, under an implicit assumption that faithful explanations come from accurate predictions/classifications. We have an opposite claim that explanations boost (or even determine) classification. That is, end-to-end learning of explanation factors to augment discriminative representation extraction could be a more intuitive strategy to inversely assure fine-grained explainability, e.g., in those neuroimaging and neuroscience studies with high-dimensional data containing noisy, redundant, and task-irrelevant information. In this paper, we propose such an explainable geometric deep network dubbed as NeuroExplainer, with applications to uncover altered infant cortical development patterns associated with preterm birth. Given fundamental cortical attributes as network input, our NeuroExplainer adopts a hierarchical attention-decoding framework to learn fine-grained attentions and respective discriminative representations to accurately recognize preterm infants from term-born infants at term-equivalent age. NeuroExplainer learns the hierarchical attention-decoding modules under subject-level weak supervision coupled with targeted regularizers deduced from domain knowledge regarding brain development. These prior-guided constraints implicitly maximizes the explainability metrics (i.e., fidelity, sparsity, and stability) in network training, driving the learned network to output detailed explanations and accurate classifications. Experimental results on the public dHCP benchmark suggest that NeuroExplainer led to quantitatively reliable explanation results that are qualitatively consistent with representative neuroimaging studies.