 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Homogenization Approach for Gradient-Dominated Stochastic Optimization
Aug 21, 2023



Gradient dominance property is a condition weaker than strong convexity, yet it sufficiently ensures global convergence for first-order methods even in non-convex optimization. This property finds application in various machine learning domains, including matrix decomposition, linear neural networks, and policy-based reinforcement learning (RL). In this paper, we study the stochastic homogeneous second-order descent method (SHSODM) for gradient-dominated optimization with $\alpha \in [1, 2]$ based on a recently proposed homogenization approach. Theoretically, we show that SHSODM achieves a sample complexity of $O(\epsilon^{-7/(2 \alpha) +1})$ for $\alpha \in [1, 3/2)$ and $\tilde{O}(\epsilon^{-2/\alpha})$ for $\alpha \in [3/2, 2]$. We further provide a SHSODM with a variance reduction technique enjoying an improved sample complexity of $O( \epsilon ^{-( 7-3\alpha ) /( 2\alpha )})$ for $\alpha \in [1,3/2)$. Our results match the state-of-the-art sample complexity bounds for stochastic gradient-dominated optimization without \emph{cubic regularization}. Since the homogenization approach only relies on solving extremal eigenvector problems instead of Newton-type systems, our methods gain the advantage of cheaper iterations and robustness in ill-conditioned problems. Numerical experiments on several RL tasks demonstrate the efficiency of SHSODM compared to other off-the-shelf methods.
DRSOM: A Dimension Reduced Second-Order Method and Preliminary Analyses
Jul 30, 2022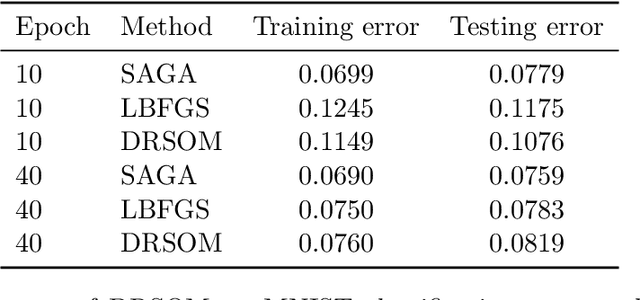

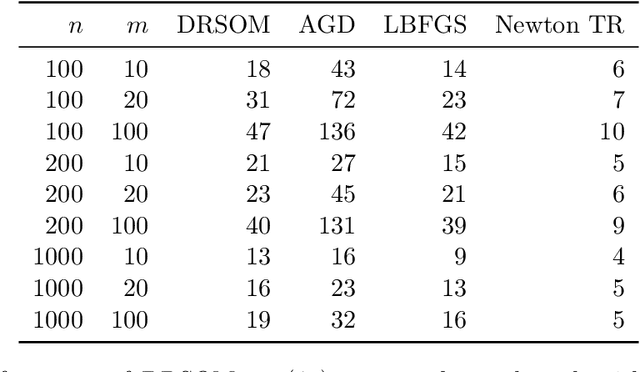

We introduce a Dimension-Reduced Second-Order Method (DRSOM) for convex and nonconvex unconstrained optimization. Under a trust-region-like framework our method preserves the convergence of the second-order method while using only Hessian-vector products in two directions. Moreover, the computational overhead remains comparable to the first-order such as the gradient descent method. We show that the method has a complexity of $O(\epsilon^{-3/2})$ to satisfy the first-order and second-order conditions in the subspace. The applicability and performance of DRSOM are exhibited by various computational experiments in logistic regression, $L_2-L_p$ minimization, sensor network localization, and neural network training. For neural networks, our preliminary implementation seems to gain computational advantages in terms of training accuracy and iteration complexity over state-of-the-art first-order methods including SGD and ADAM.