 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation-aware Hierarchical Attention Framework for Video Question Answering
May 14, 2021
Video Question Answering (VideoQA) is a challenging video understanding task since it requires a deep understanding of both question and video. Previous studies mainly focus on extracting sophisticated visual and language embeddings, fusing them by delicate hand-crafted networks. However, the relevance of different frames, objects, and modalities to the question are varied along with the time, which is ignored in most of existing methods. Lacking understanding of the the dynamic relationships and interactions among objects brings a great challenge to VideoQA task. To address this problem, we propose a novel Relation-aware Hierarchical Attention (RHA) framework to learn both the static and dynamic relations of the objects in videos. In particular, videos and questions are embedded by pre-trained models firstly to obtain the visual and textual features. Then a graph-based relation encoder is utilized to extract the static relationship between visual objects. To capture the dynamic changes of multimodal objects in different video frames, we consider the temporal, spatial, and semantic relations, and fuse the multimodal features by hierarchical attention mechanism to predict the answer. We conduct extensive experiments on a large scale VideoQA dataset, and the experimental results demonstrate that our RHA outperforms the state-of-the-art methods.
Frame Aggregation and Multi-Modal Fusion Framework for Video-Based Person Recognition
Oct 19, 2020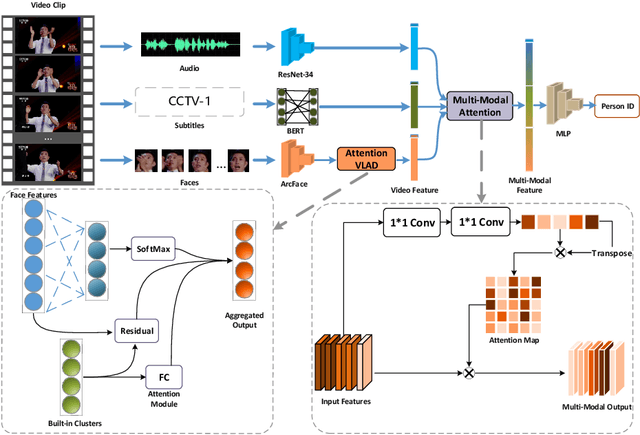
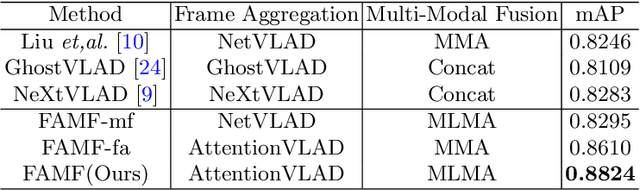

Video-based person recognition is challenging due to persons being blocked and blurred, and the variation of shooting angle. Previous research always focused on person recognition on still images, ignoring similarity and continuity between video frames. To tackle the challenges above, we propose a novel Frame Aggregation and Multi-Modal Fusion (FAMF) framework for video-based person recognition, which aggregates face features and incorporates them with multi-modal information to identify persons in videos. For frame aggregation, we propose a novel trainable layer based on NetVLAD (named AttentionVLAD), which takes arbitrary number of features as input and computes a fixed-length aggregation feature based on feature quality. We show that introducing an attention mechanism to NetVLAD can effectively decrease the impact of low-quality frames. For the multi-model information of videos, we propose a Multi-Layer Multi-Modal Attention (MLMA) module to learn the correlation of multi-modality by adaptively updating Gram matrix. Experimental results on iQIYI-VID-2019 dataset show that our framework outperforms other state-of-the-art methods.