 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrame Aggregation and Multi-Modal Fusion Framework for Video-Based Person Recognition
Paper and Code
Oct 19, 2020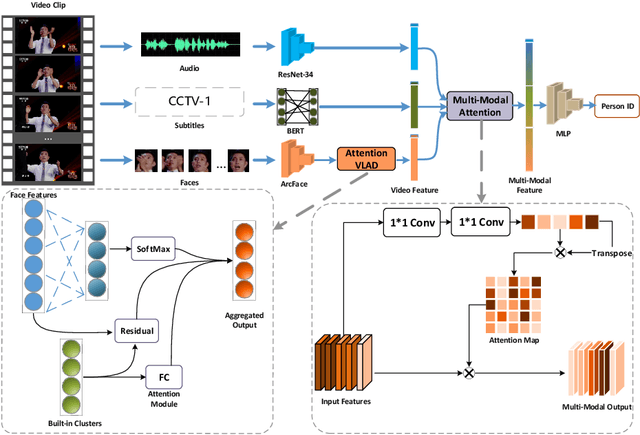
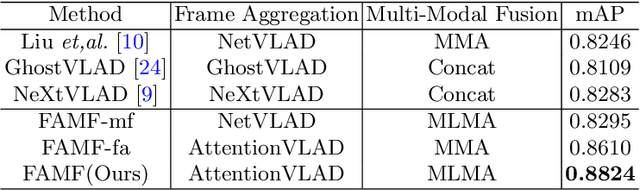

Video-based person recognition is challenging due to persons being blocked and blurred, and the variation of shooting angle. Previous research always focused on person recognition on still images, ignoring similarity and continuity between video frames. To tackle the challenges above, we propose a novel Frame Aggregation and Multi-Modal Fusion (FAMF) framework for video-based person recognition, which aggregates face features and incorporates them with multi-modal information to identify persons in videos. For frame aggregation, we propose a novel trainable layer based on NetVLAD (named AttentionVLAD), which takes arbitrary number of features as input and computes a fixed-length aggregation feature based on feature quality. We show that introducing an attention mechanism to NetVLAD can effectively decrease the impact of low-quality frames. For the multi-model information of videos, we propose a Multi-Layer Multi-Modal Attention (MLMA) module to learn the correlation of multi-modality by adaptively updating Gram matrix. Experimental results on iQIYI-VID-2019 dataset show that our framework outperforms other state-of-the-art methods.