 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxelized 3D Feature Aggregation for Multiview Detection
Paper and Code

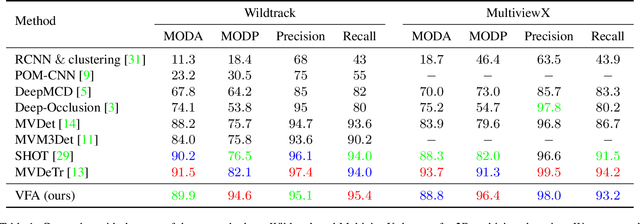


Multi-view detection incorporates multiple camera views to alleviate occlusion in crowded scenes, where the state-of-the-art approaches adopt homography transformations to project multi-view features to the ground plane. However, we find that these 2D transformations do not take into account the object's height, and with this neglection features along the vertical direction of same object are likely not projected onto the same ground plane point, leading to impure ground-plane features. To solve this problem, we propose VFA, voxelized 3D feature aggregation, for feature transformation and aggregation in multi-view detection. Specifically, we voxelize the 3D space, project the voxels onto each camera view, and associate 2D features with these projected voxels. This allows us to identify and then aggregate 2D features along the same vertical line, alleviating projection distortions to a large extent. Additionally, because different kinds of objects (human vs. cattle) have different shapes on the ground plane, we introduce the oriented Gaussian encoding to match such shapes, leading to increased accuracy and efficiency. We perform experiments on multiview 2D detection and multiview 3D detection problems. Results on four datasets (including a newly introduced MultiviewC dataset) show that our system is very competitive compared with the state-of-the-art approaches. %Our code and data will be open-sourced.Code and MultiviewC are released at https://github.com/Robert-Mar/VFA.