 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseLGS: Sparse View Language Embedded Gaussian Splatting
Paper and Code


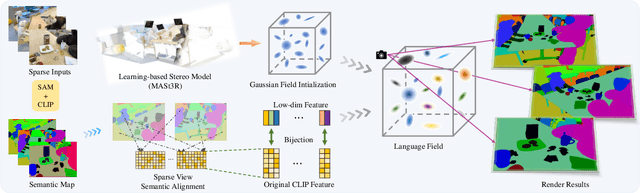
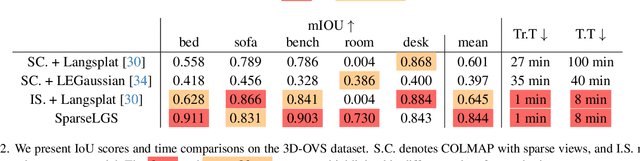
Recently, several studies have combined Gaussian Splatting to obtain scene representations with language embeddings for open-vocabulary 3D scene understanding. While these methods perform well, they essentially require very dense multi-view inputs, limiting their applicability in real-world scenarios. In this work, we propose SparseLGS to address the challenge of 3D scene understanding with pose-free and sparse view input images. Our method leverages a learning-based dense stereo model to handle pose-free and sparse inputs, and a three-step region matching approach to address the multi-view semantic inconsistency problem, which is especially important for sparse inputs. Different from directly learning high-dimensional CLIP features, we extract low-dimensional information and build bijections to avoid excessive learning and storage costs. We introduce a reconstruction loss during semantic training to improve Gaussian positions and shapes. To the best of our knowledge, we are the first to address the 3D semantic field problem with sparse pose-free inputs. Experimental results show that SparseLGS achieves comparable quality when reconstructing semantic fields with fewer inputs (3-4 views) compared to previous SOTA methods with dense input. Besides, when using the same sparse input, SparseLGS leads significantly in quality and heavily improves the computation speed (5$\times$ speedup). Project page: {\tt\small \url{https://ustc3dv.github.io/SparseLGS}}