 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGL: A Graph-Centric, Modular Framework for Efficient Retrieval-Augmented Generation on Graphs
Mar 25, 2025Recent advances in graph learning have paved the way for innovative retrieval-augmented generation (RAG) systems that leverage the inherent relational structures in graph data. However, many existing approaches suffer from rigid, fixed settings and significant engineering overhead, limiting their adaptability and scalability. Additionally, the RAG community has largely overlooked the decades of research in the graph database community regarding the efficient retrieval of interesting substructures on large-scale graphs. In this work, we introduce the RAG-on-Graphs Library (RGL), a modular framework that seamlessly integrates the complete RAG pipeline-from efficient graph indexing and dynamic node retrieval to subgraph construction, tokenization, and final generation-into a unified system. RGL addresses key challenges by supporting a variety of graph formats and integrating optimized implementations for essential components, achieving speedups of up to 143x compared to conventional methods. Moreover, its flexible utilities, such as dynamic node filtering, allow for rapid extraction of pertinent subgraphs while reducing token consumption. Our extensive evaluations demonstrate that RGL not only accelerates the prototyping process but also enhances the performance and applicability of graph-based RAG systems across a range of tasks.
Diffusion-based Semi-supervised Spectral Algorithm for Regression on Manifolds
Oct 18, 2024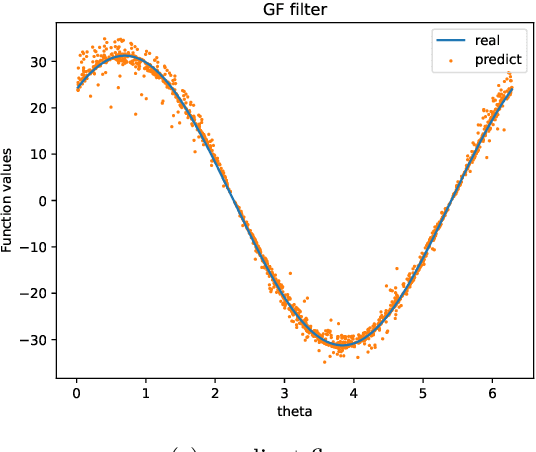
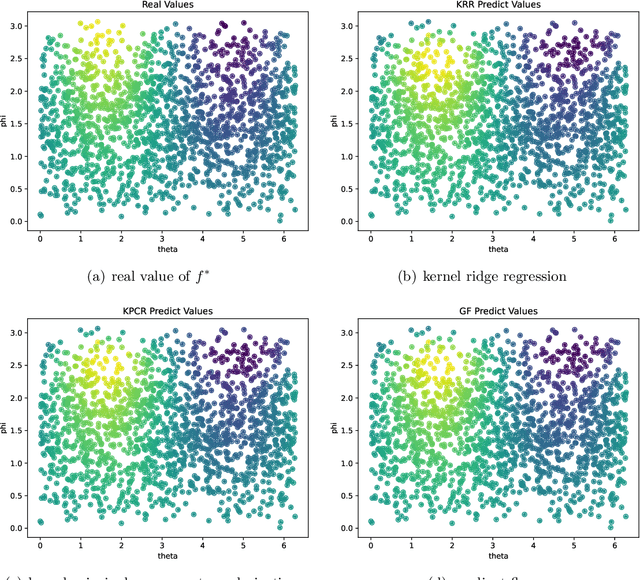
We introduce a novel diffusion-based spectral algorithm to tackle regression analysis on high-dimensional data, particularly data embedded within lower-dimensional manifolds. Traditional spectral algorithms often fall short in such contexts, primarily due to the reliance on predetermined kernel functions, which inadequately address the complex structures inherent in manifold-based data. By employing graph Laplacian approximation, our method uses the local estimation property of heat kernel, offering an adaptive, data-driven approach to overcome this obstacle. Another distinct advantage of our algorithm lies in its semi-supervised learning framework, enabling it to fully use the additional unlabeled data. This ability enhances the performance by allowing the algorithm to dig the spectrum and curvature of the data manifold, providing a more comprehensive understanding of the dataset. Moreover, our algorithm performs in an entirely data-driven manner, operating directly within the intrinsic manifold structure of the data, without requiring any predefined manifold information. We provide a convergence analysis of our algorithm. Our findings reveal that the algorithm achieves a convergence rate that depends solely on the intrinsic dimension of the underlying manifold, thereby avoiding the curse of dimensionality associated with the higher ambient dimension.