 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Multi-Label Classification under Noisy and Changing Label Distribution
Oct 03, 2024Multi-label data stream usually contains noisy labels in the real-world applications, namely occuring in both relevant and irrelevant labels. However, existing online multi-label classification methods are mostly limited in terms of label quality and fail to deal with the case of noisy labels. On the other hand, the ground-truth label distribution may vary with the time changing, which is hidden in the observed noisy label distribution and difficult to track, posing a major challenge for concept drift adaptation. Motivated by this, we propose an online multi-label classification algorithm under Noisy and Changing Label Distribution (NCLD). The convex objective is designed to simultaneously model the label scoring and the label ranking for high accuracy, whose robustness to NCLD benefits from three novel works: 1) The local feature graph is used to reconstruct the label scores jointly with the observed labels, and an unbiased ranking loss is derived and applied to learn reliable ranking information. 2) By detecting the difference between two adjacent chunks with the unbiased label cardinality, we identify the change in the ground-truth label distribution and reset the ranking or all information learned from the past to match the new distribution. 3) Efficient and accurate updating is achieved based on the updating rule derived from the closed-form optimal model solution. Finally, empirical experimental results validate the effectiveness of our method in classifying instances under NCLD.
Semi-supervised representation learning via dual autoencoders for domain adaptation
Aug 04, 2019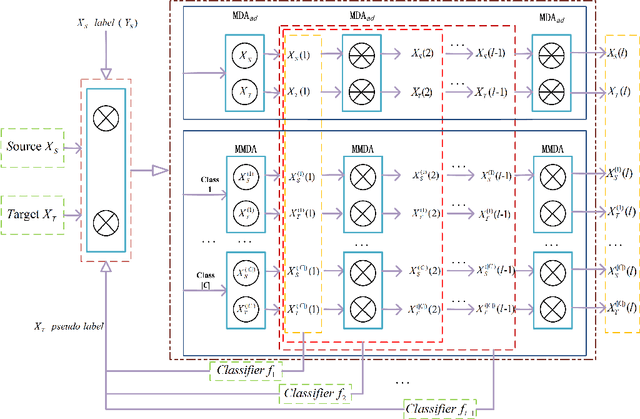
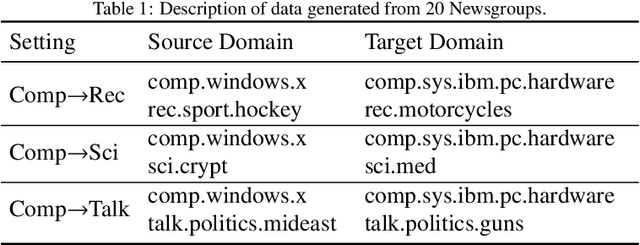
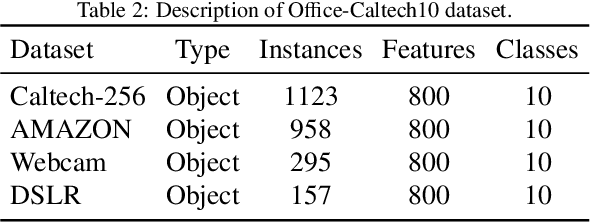
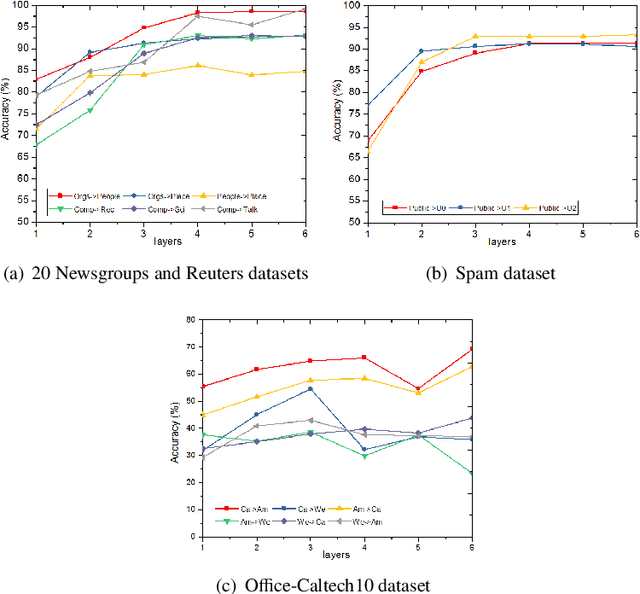
Domain adaptation which pays attention to exploiting the knowledge in source domain to promote the learning tasks in target domain plays a critical role in real-world applications. Recently, lots of deep learning approaches based on autoencoders have achieved significance performance in domain adaptation. However, most existing methods focus on minimizing the distribution divergence by putting the source data and target data together to learn global feature representations, while do not take the local relationship between instances of the same category in different domains into account. To address this problem, we propose a novel Semi-Supervised Representation Learning framework via Dual Autoencoders for domain adaptation, named SSRLDA. More specifically, \textcolor{red}{we extract richer feature representations by learning the global and local feature representations simultaneously using two novel autoencoders}, which are referred to as marginalized denoising autoencoder with adaptation distribution (MDA$_{ad}$) and multi-class marginalized denoising autoencoder (MMDA) respectively. Meanwhile, we \textcolor{red}{adopt an iterative strategy} to make full use of label information to optimize feature representations. Experimental results show that our proposed approach outperforms several state-of-the-art baseline methods.
Online Feature Selection with Group Structure Analysis
Aug 21, 2016


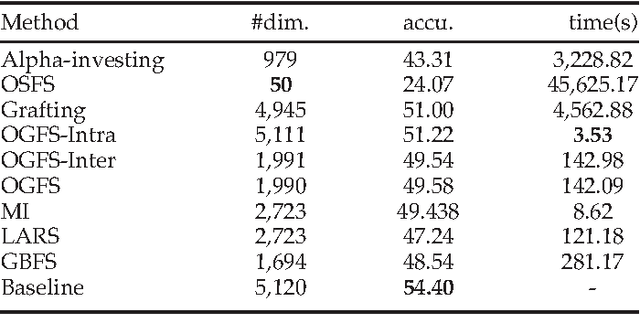
Online selection of dynamic features has attracted intensive interest in recent years. However, existing online feature selection methods evaluate features individually and ignore the underlying structure of feature stream. For instance, in image analysis, features are generated in groups which represent color, texture and other visual information. Simply breaking the group structure in feature selection may degrade performance. Motivated by this fact, we formulate the problem as an online group feature selection. The problem assumes that features are generated individually but there are group structure in the feature stream. To the best of our knowledge, this is the first time that the correlation among feature stream has been considered in the online feature selection process. To solve this problem, we develop a novel online group feature selection method named OGFS. Our proposed approach consists of two stages: online intra-group selection and online inter-group selection. In the intra-group selection, we design a criterion based on spectral analysis to select discriminative features in each group. In the inter-group selection, we utilize a linear regression model to select an optimal subset. This two-stage procedure continues until there are no more features arriving or some predefined stopping conditions are met. %Our method has been applied Finally, we apply our method to multiple tasks including image classification %, face verification and face verification. Extensive empirical studies performed on real-world and benchmark data sets demonstrate that our method outperforms other state-of-the-art online feature selection %method methods.
Visual Processing by a Unified Schatten-$p$ Norm and $\ell_q$ Norm Regularized Principal Component Pursuit
Aug 20, 2016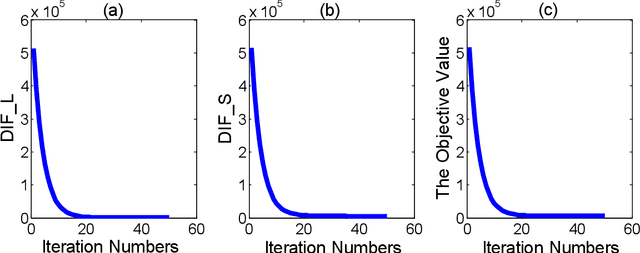
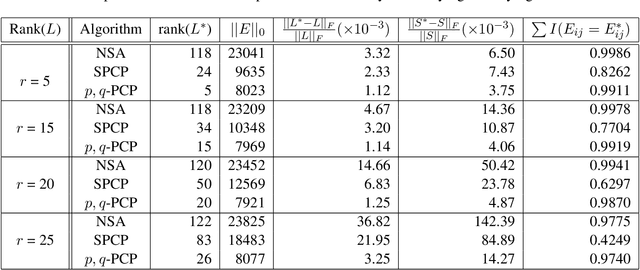
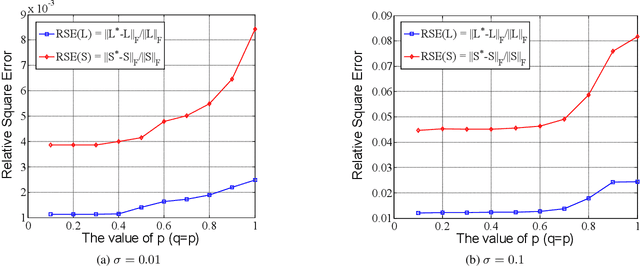
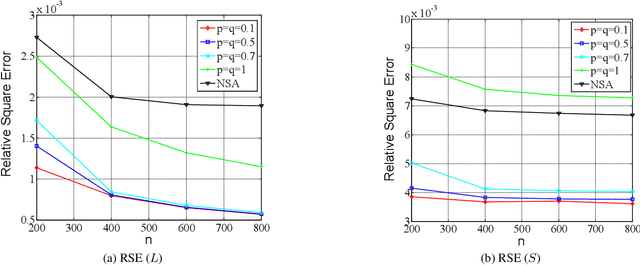
In this paper, we propose a non-convex formulation to recover the authentic structure from the corrupted real data. Typically, the specific structure is assumed to be low rank, which holds for a wide range of data, such as images and videos. Meanwhile, the corruption is assumed to be sparse. In the literature, such a problem is known as Robust Principal Component Analysis (RPCA), which usually recovers the low rank structure by approximating the rank function with a nuclear norm and penalizing the error by an $\ell_1$-norm. Although RPCA is a convex formulation and can be solved effectively, the introduced norms are not tight approximations, which may cause the solution to deviate from the authentic one. Therefore, we consider here a non-convex relaxation, consisting of a Schatten-$p$ norm and an $\ell_q$-norm that promote low rank and sparsity respectively. We derive a proximal iteratively reweighted algorithm (PIRA) to solve the problem. Our algorithm is based on an alternating direction method of multipliers, where in each iteration we linearize the underlying objective function that allows us to have a closed form solution. We demonstrate that solutions produced by the linearized approximation always converge and have a tighter approximation than the convex counterpart. Experimental results on benchmarks show encouraging results of our approach.
Robust Face Recognition via Adaptive Sparse Representation
Apr 18, 2014

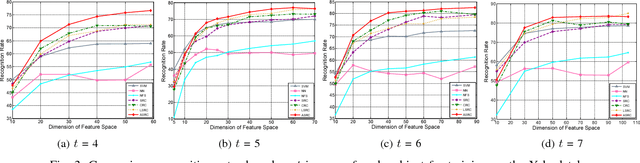

Sparse Representation (or coding) based Classification (SRC) has gained great success in face recognition in recent years. However, SRC emphasizes the sparsity too much and overlooks the correlation information which has been demonstrated to be critical in real-world face recognition problems. Besides, some work considers the correlation but overlooks the discriminative ability of sparsity. Different from these existing techniques, in this paper, we propose a framework called Adaptive Sparse Representation based Classification (ASRC) in which sparsity and correlation are jointly considered. Specifically, when the samples are of low correlation, ASRC selects the most discriminative samples for representation, like SRC; when the training samples are highly correlated, ASRC selects most of the correlated and discriminative samples for representation, rather than choosing some related samples randomly. In general, the representation model is adaptive to the correlation structure, which benefits from both $\ell_1$-norm and $\ell_2$-norm. Extensive experiments conducted on publicly available data sets verify the effectiveness and robustness of the proposed algorithm by comparing it with state-of-the-art methods.