 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Ripple Effects in Knowledge Editing through Pressure-Aware Joint Neighborhood Optimization
Jun 01, 2026Single-edit updates in large language models can trigger ripple effects across local knowledge neighborhoods: desirable propagation to related facts and unintended perturbation of preserved ones. Existing methods address these two effects separately, without explicitly modeling their coupling. We challenge this separation through an analysis of ripple responses across typical baselines, identifying two coupled design pressures: editable-side coordination and preserved-side leakage. We propose Joint Neighborhood Optimization (JNO), a new knowledge-editing framework to formalize and jointly address both pressures at the target-planning stage. JNO instantiates this principle through Pressure-Aware Coordination (PAC), which jointly optimizes neighborhood target representations under coupled constraints, and a semantic pre-execution gate that rejects high-risk target plans before parameter execution. Experiments on RippleEdits show JNO improves propagation and preservation metrics by at least 7.0% while preserving cross-backbone editing stability.
From Coarse to Nuanced: Cross-Modal Alignment of Fine-Grained Linguistic Cues and Visual Salient Regions for Dynamic Emotion Recognition
Jul 16, 2025Dynamic Facial Expression Recognition (DFER) aims to identify human emotions from temporally evolving facial movements and plays a critical role in affective computing. While recent vision-language approaches have introduced semantic textual descriptions to guide expression recognition, existing methods still face two key limitations: they often underutilize the subtle emotional cues embedded in generated text, and they have yet to incorporate sufficiently effective mechanisms for filtering out facial dynamics that are irrelevant to emotional expression. To address these gaps, We propose GRACE, Granular Representation Alignment for Cross-modal Emotion recognition that integrates dynamic motion modeling, semantic text refinement, and token-level cross-modal alignment to facilitate the precise localization of emotionally salient spatiotemporal features. Our method constructs emotion-aware textual descriptions via a Coarse-to-fine Affective Text Enhancement (CATE) module and highlights expression-relevant facial motion through a motion-difference weighting mechanism. These refined semantic and visual signals are aligned at the token level using entropy-regularized optimal transport. Experiments on three benchmark datasets demonstrate that our method significantly improves recognition performance, particularly in challenging settings with ambiguous or imbalanced emotion classes, establishing new state-of-the-art (SOTA) results in terms of both UAR and WAR.
Data Poisoning in Deep Learning: A Survey
Mar 27, 2025



Deep learning has become a cornerstone of modern artificial intelligence, enabling transformative applications across a wide range of domains. As the core element of deep learning, the quality and security of training data critically influence model performance and reliability. However, during the training process, deep learning models face the significant threat of data poisoning, where attackers introduce maliciously manipulated training data to degrade model accuracy or lead to anomalous behavior. While existing surveys provide valuable insights into data poisoning, they generally adopt a broad perspective, encompassing both attacks and defenses, but lack a dedicated, in-depth analysis of poisoning attacks specifically in deep learning. In this survey, we bridge this gap by presenting a comprehensive and targeted review of data poisoning in deep learning. First, this survey categorizes data poisoning attacks across multiple perspectives, providing an in-depth analysis of their characteristics and underlying design princinples. Second, the discussion is extended to the emerging area of data poisoning in large language models(LLMs). Finally, we explore critical open challenges in the field and propose potential research directions to advance the field further. To support further exploration, an up-to-date repository of resources on data poisoning in deep learning is available at https://github.com/Pinlong-Zhao/Data-Poisoning.
Private Knowledge Transfer via Model Distillation with Generative Adversarial Networks
Apr 05, 2020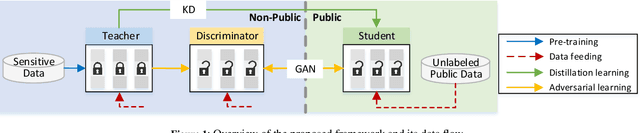

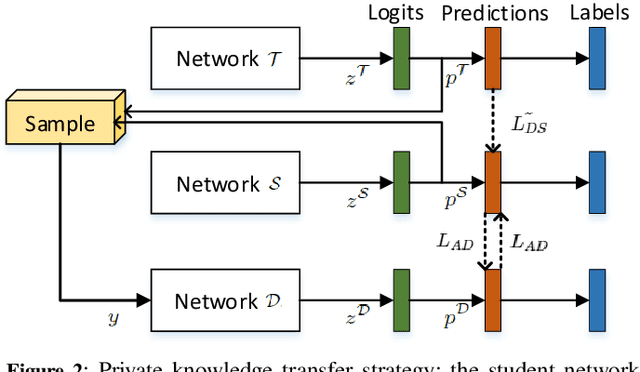
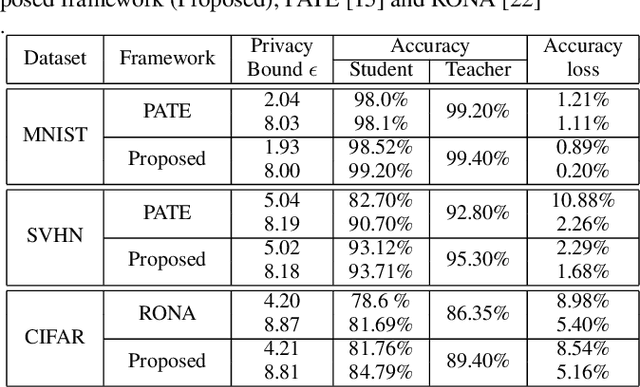
The deployment of deep learning applications has to address the growing privacy concerns when using private and sensitive data for training. A conventional deep learning model is prone to privacy attacks that can recover the sensitive information of individuals from either model parameters or accesses to the target model. Recently, differential privacy that offers provable privacy guarantees has been proposed to train neural networks in a privacy-preserving manner to protect training data. However, many approaches tend to provide the worst case privacy guarantees for model publishing, inevitably impairing the accuracy of the trained models. In this paper, we present a novel private knowledge transfer strategy, where the private teacher trained on sensitive data is not publicly accessible but teaches a student to be publicly released. In particular, a three-player (teacher-student-discriminator) learning framework is proposed to achieve trade-off between utility and privacy, where the student acquires the distilled knowledge from the teacher and is trained with the discriminator to generate similar outputs as the teacher. We then integrate a differential privacy protection mechanism into the learning procedure, which enables a rigorous privacy budget for the training. The framework eventually allows student to be trained with only unlabelled public data and very few epochs, and hence prevents the exposure of sensitive training data, while ensuring model utility with a modest privacy budget. The experiments on MNIST, SVHN and CIFAR-10 datasets show that our students obtain the accuracy losses w.r.t teachers of 0.89%, 2.29%, 5.16%, respectively with the privacy bounds of (1.93, 10^-5), (5.02, 10^-6), (8.81, 10^-6). When compared with the existing works \cite{papernot2016semi,wang2019private}, the proposed work can achieve 5-82% accuracy loss improvement.
A Comparative Study for Non-rigid Image Registration and Rigid Image Registration
Jan 12, 2020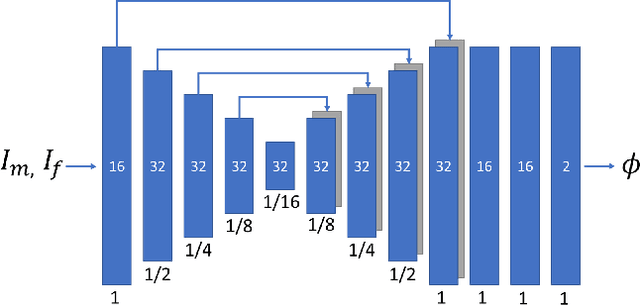
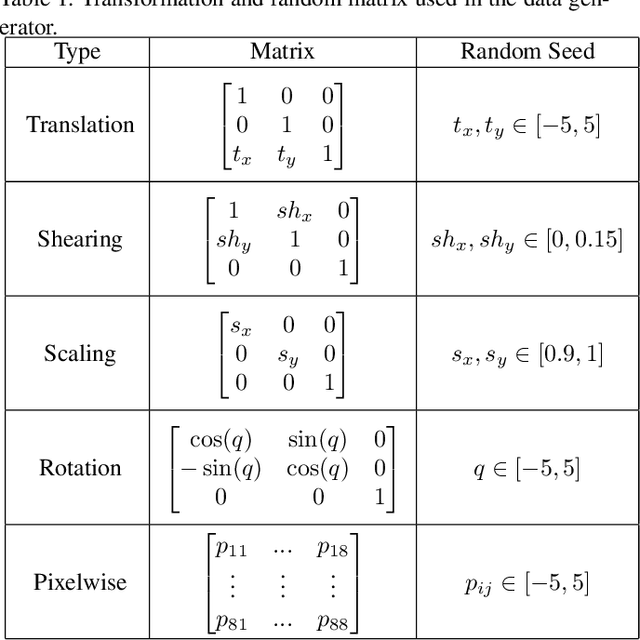
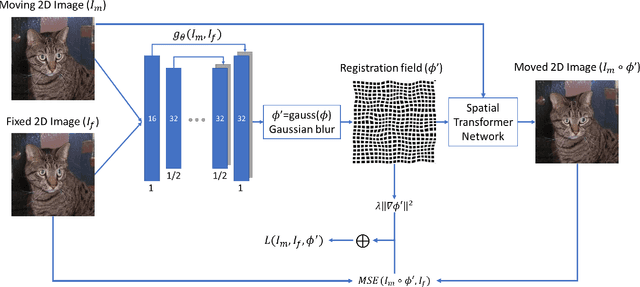

Image registration algorithms can be generally categorized into two groups: non-rigid and rigid. Recently, many deep learning-based algorithms employ a neural net to characterize non-rigid image registration function. However, do they always perform better? In this study, we compare the state-of-art deep learning-based non-rigid registration approach with rigid registration approach. The data is generated from Kaggle Dog vs Cat Competition \url{https://www.kaggle.com/c/dogs-vs-cats/} and we test the algorithms' performance on rigid transformation including translation, rotation, scaling, shearing and pixelwise non-rigid transformation. The Voxelmorph is trained on rigidset and nonrigidset separately for comparison and we also add a gaussian blur layer to its original architecture to improve registration performance. The best quantitative results in both root-mean-square error (RMSE) and mean absolute error (MAE) metrics for rigid registration are produced by SimpleElastix and non-rigid registration by Voxelmorph. We select representative samples for visual assessment.