 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Multi-Domain Graph Pre-training for Homogeneous and Heterogeneous Graphs via Domain-Specific Expert Encoding
Feb 13, 2026Graph pre-training has achieved remarkable success in recent years, delivering transferable representations for downstream adaptation. However, most existing methods are designed for either homogeneous or heterogeneous graphs, thereby hindering unified graph modeling across diverse graph types. This separation contradicts real-world applications, where mixed homogeneous and heterogeneous graphs are ubiquitous, and distribution shifts between upstream pre-training and downstream deployment are common. In this paper, we empirically demonstrate that a balanced mixture of homogeneous and heterogeneous graph pre-training benefits downstream tasks and propose a unified multi-domain \textbf{G}raph \textbf{P}re-training method across \textbf{H}omogeneous and \textbf{H}eterogeneous graphs ($\mathbf{GPH^{2}}$). To address the lack of a unified encoder for homogeneous and heterogeneous graphs, we propose a Unified Multi-View Graph Construction that simultaneously encodes both without explicit graph-type-specific designs. To cope with the increased cross-domain distribution discrepancies arising from mixed graphs, we introduce domain-specific expert encoding. Each expert is independently pre-trained on a single graph to capture domain-specific knowledge, thereby shielding the pre-training encoder from the adverse effects of cross-domain discrepancies. For downstream tasks, we further design a Task-oriented Expert Fusion Strategy that adaptively integrates multiple experts based on their discriminative strengths. Extensive experiments on mixed graphs demonstrate that $\text{GPH}^{2}$ enables stable transfer across graph types and domains, significantly outperforming existing graph pre-training methods.
TrustGNN: Graph Neural Network based Trust Evaluation via Learnable Propagative and Composable Nature
May 25, 2022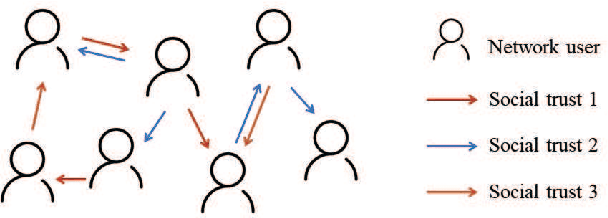
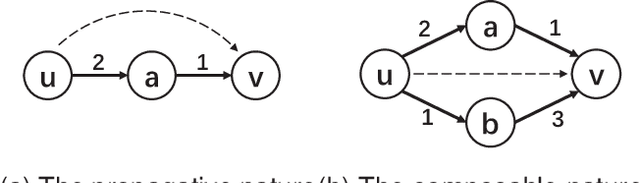
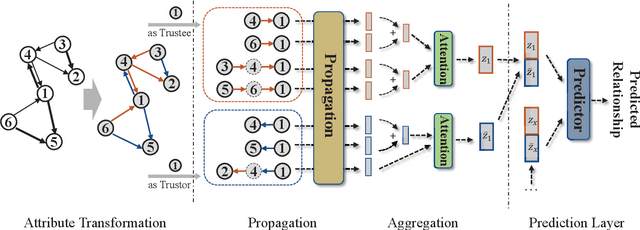
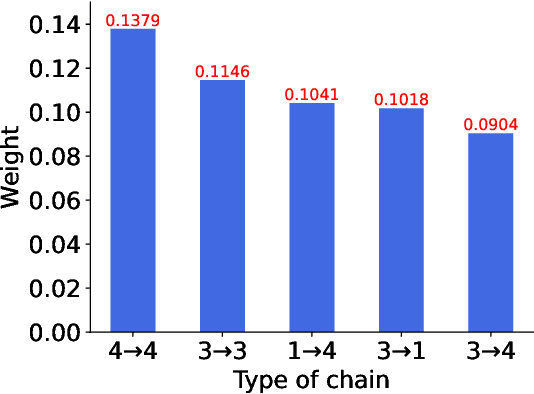
Trust evaluation is critical for many applications such as cyber security, social communication and recommender systems. Users and trust relationships among them can be seen as a graph. Graph neural networks (GNNs) show their powerful ability for analyzing graph-structural data. Very recently, existing work attempted to introduce the attributes and asymmetry of edges into GNNs for trust evaluation, while failed to capture some essential properties (e.g., the propagative and composable nature) of trust graphs. In this work, we propose a new GNN based trust evaluation method named TrustGNN, which integrates smartly the propagative and composable nature of trust graphs into a GNN framework for better trust evaluation. Specifically, TrustGNN designs specific propagative patterns for different propagative processes of trust, and distinguishes the contribution of different propagative processes to create new trust. Thus, TrustGNN can learn comprehensive node embeddings and predict trust relationships based on these embeddings. Experiments on some widely-used real-world datasets indicate that TrustGNN significantly outperforms the state-of-the-art methods. We further perform analytical experiments to demonstrate the effectiveness of the key designs in TrustGNN.
Block Modeling-Guided Graph Convolutional Neural Networks
Dec 28, 2021
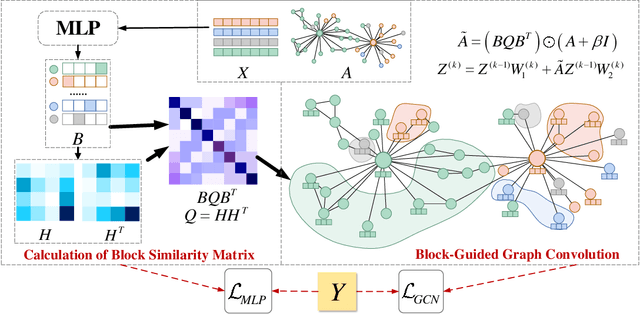
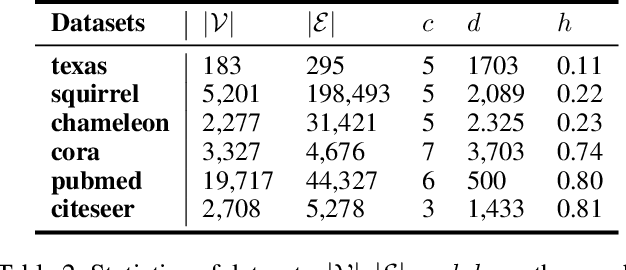
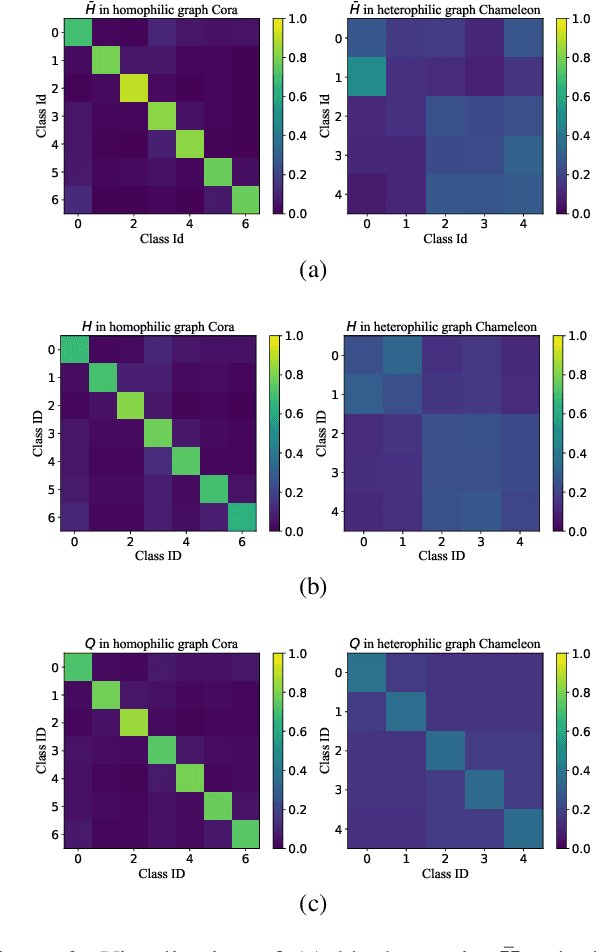
Graph Convolutional Network (GCN) has shown remarkable potential of exploring graph representation. However, the GCN aggregating mechanism fails to generalize to networks with heterophily where most nodes have neighbors from different classes, which commonly exists in real-world networks. In order to make the propagation and aggregation mechanism of GCN suitable for both homophily and heterophily (or even their mixture), we introduce block modeling into the framework of GCN so that it can realize "block-guided classified aggregation", and automatically learn the corresponding aggregation rules for neighbors of different classes. By incorporating block modeling into the aggregation process, GCN is able to aggregate information from homophilic and heterophilic neighbors discriminately according to their homophily degree. We compared our algorithm with state-of-art methods which deal with the heterophily problem. Empirical results demonstrate the superiority of our new approach over existing methods in heterophilic datasets while maintaining a competitive performance in homophilic datasets.