 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-trained Token-replaced Detection Model as Few-shot Learner
Paper and Code
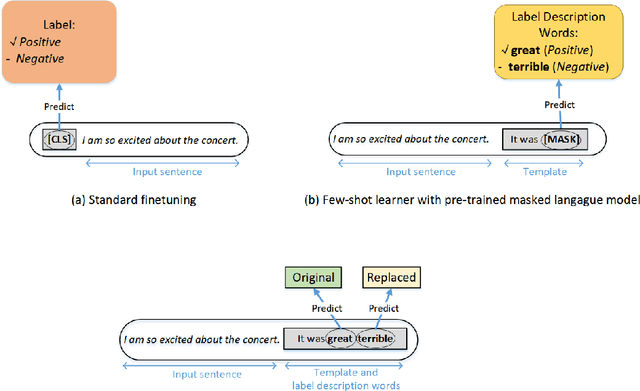
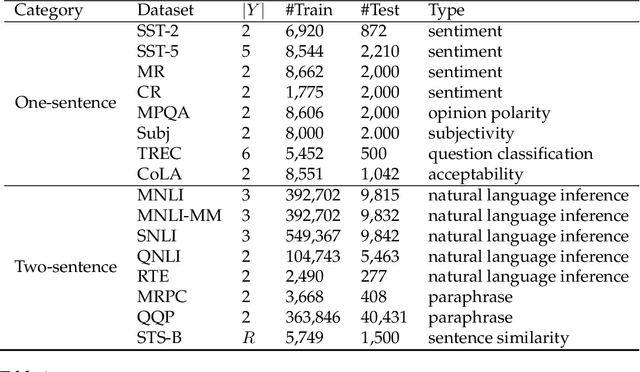
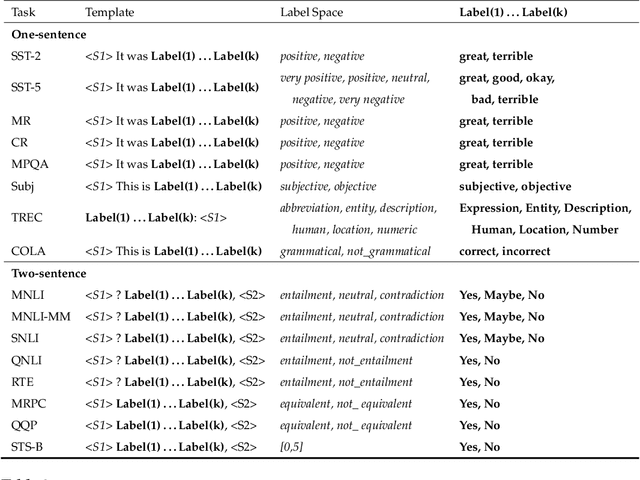

Pre-trained masked language models have demonstrated remarkable ability as few-shot learners. In this paper, as an alternative, we propose a novel approach to few-shot learning with pre-trained token-replaced detection models like ELECTRA. In this approach, we reformulate a classification or a regression task as a token-replaced detection problem. Specifically, we first define a template and label description words for each task and put them into the input to form a natural language prompt. Then, we employ the pre-trained token-replaced detection model to predict which label description word is the most original (i.e., least replaced) among all label description words in the prompt. A systematic evaluation on 16 datasets demonstrates that our approach outperforms few-shot learners with pre-trained masked language models in both one-sentence and two-sentence learning tasks.