 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-class Probabilistic Bounds for Self-learning
Paper and Code

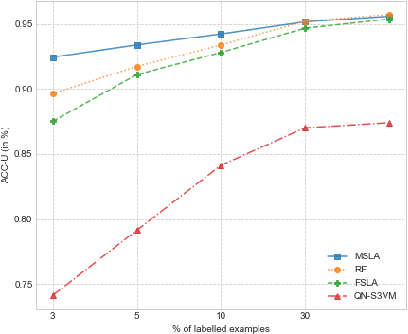
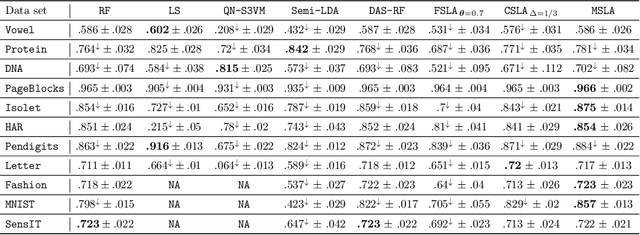

Self-learning is a classical approach for learning with both labeled and unlabeled observations which consists in giving pseudo-labels to unlabeled training instances with a confidence score over a predetermined threshold. At the same time, the pseudo-labeling technique is prone to error and runs the risk of adding noisy labels into unlabeled training data. In this paper, we present a probabilistic framework for analyzing self-learning in the multi-class classification scenario with partially labeled data. First, we derive a transductive bound over the risk of the multi-class majority vote classifier. Based on this result, we propose to automatically choose the threshold for pseudo-labeling that minimizes the transductive bound. Then, we introduce a mislabeling error model to analyze the error of the majority vote classifier in the case of the pseudo-labeled data. We derive a probabilistic C-bound over the majority vote error when an imperfect label is given. Empirical results on different data sets show the effectiveness of our framework compared to several state-of-the-art semi-supervised approaches.