 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Series Representations for Classification Lie Hidden in Pretrained Vision Transformers
Jun 10, 2025Time series classification is a fundamental task in healthcare and industry, yet the development of time series foundation models (TSFMs) remains limited by the scarcity of publicly available time series datasets. In this work, we propose Time Vision Transformer (TiViT), a framework that converts time series into images to leverage the representational power of frozen Vision Transformers (ViTs) pretrained on large-scale image datasets. First, we theoretically motivate our approach by analyzing the 2D patching of ViTs for time series, showing that it can increase the number of label-relevant tokens and reduce the sample complexity. Second, we empirically demonstrate that TiViT achieves state-of-the-art performance on standard time series classification benchmarks by utilizing the hidden representations of large OpenCLIP models. We explore the structure of TiViT representations and find that intermediate layers with high intrinsic dimension are the most effective for time series classification. Finally, we assess the alignment between TiViT and TSFM representation spaces and identify a strong complementarity, with further performance gains achieved by combining their features. Our findings reveal yet another direction for reusing vision representations in a non-visual domain.
Shortcut Detection with Variational Autoencoders
Feb 08, 2023For real-world applications of machine learning (ML), it is essential that models make predictions based on well-generalizing features rather than spurious correlations in the data. The identification of such spurious correlations, also known as shortcuts, is a challenging problem and has so far been scarcely addressed. In this work, we present a novel approach to detect shortcuts in image and audio datasets by leveraging variational autoencoders (VAEs). The disentanglement of features in the latent space of VAEs allows us to discover correlations in datasets and semi-automatically evaluate them for ML shortcuts. We demonstrate the applicability of our method on several real-world datasets and identify shortcuts that have not been discovered before. Based on these findings, we also investigate the construction of shortcut adversarial examples.
Defending against Adversarial Denial-of-Service Attacks
Apr 21, 2021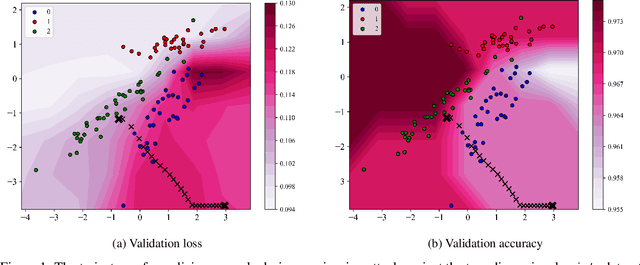
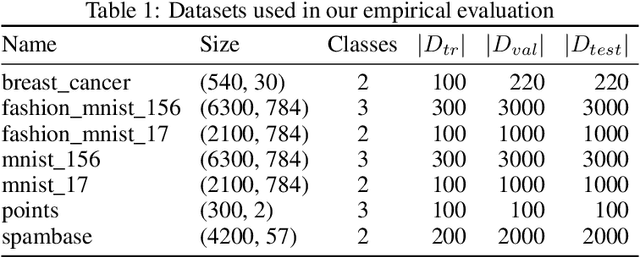


Data poisoning is one of the most relevant security threats against machine learning and data-driven technologies. Since many applications rely on untrusted training data, an attacker can easily craft malicious samples and inject them into the training dataset to degrade the performance of machine learning models. As recent work has shown, such Denial-of-Service (DoS) data poisoning attacks are highly effective. To mitigate this threat, we propose a new approach of detecting DoS poisoned instances. In comparison to related work, we deviate from clustering and anomaly detection based approaches, which often suffer from the curse of dimensionality and arbitrary anomaly threshold selection. Rather, our defence is based on extracting information from the training data in such a generalized manner that we can identify poisoned samples based on the information present in the unpoisoned portion of the data. We evaluate our defence against two DoS poisoning attacks and seven datasets, and find that it reliably identifies poisoned instances. In comparison to related work, our defence improves false positive / false negative rates by at least 50%, often more.