 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniMax-Speech: Intrinsic Zero-Shot Text-to-Speech with a Learnable Speaker Encoder
May 12, 2025We introduce MiniMax-Speech, an autoregressive Transformer-based Text-to-Speech (TTS) model that generates high-quality speech. A key innovation is our learnable speaker encoder, which extracts timbre features from a reference audio without requiring its transcription. This enables MiniMax-Speech to produce highly expressive speech with timbre consistent with the reference in a zero-shot manner, while also supporting one-shot voice cloning with exceptionally high similarity to the reference voice. In addition, the overall quality of the synthesized audio is enhanced through the proposed Flow-VAE. Our model supports 32 languages and demonstrates excellent performance across multiple objective and subjective evaluations metrics. Notably, it achieves state-of-the-art (SOTA) results on objective voice cloning metrics (Word Error Rate and Speaker Similarity) and has secured the top position on the public TTS Arena leaderboard. Another key strength of MiniMax-Speech, granted by the robust and disentangled representations from the speaker encoder, is its extensibility without modifying the base model, enabling various applications such as: arbitrary voice emotion control via LoRA; text to voice (T2V) by synthesizing timbre features directly from text description; and professional voice cloning (PVC) by fine-tuning timbre features with additional data. We encourage readers to visit https://minimax-ai.github.io/tts_tech_report for more examples.
Approximate Global Convergence of Independent Learning in Multi-Agent Systems
May 30, 2024Independent learning (IL), despite being a popular approach in practice to achieve scalability in large-scale multi-agent systems, usually lacks global convergence guarantees. In this paper, we study two representative algorithms, independent $Q$-learning and independent natural actor-critic, within value-based and policy-based frameworks, and provide the first finite-sample analysis for approximate global convergence. The results imply a sample complexity of $\tilde{\mathcal{O}}(\epsilon^{-2})$ up to an error term that captures the dependence among agents and characterizes the fundamental limit of IL in achieving global convergence. To establish the result, we develop a novel approach for analyzing IL by constructing a separable Markov decision process (MDP) for convergence analysis and then bounding the gap due to model difference between the separable MDP and the original one. Moreover, we conduct numerical experiments using a synthetic MDP and an electric vehicle charging example to verify our theoretical findings and to demonstrate the practical applicability of IL.
Sparse-view CT Reconstruction with 3D Gaussian Volumetric Representation
Dec 25, 2023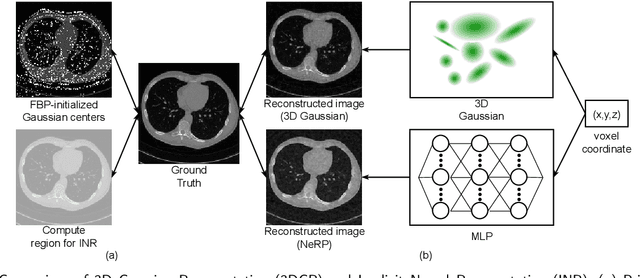
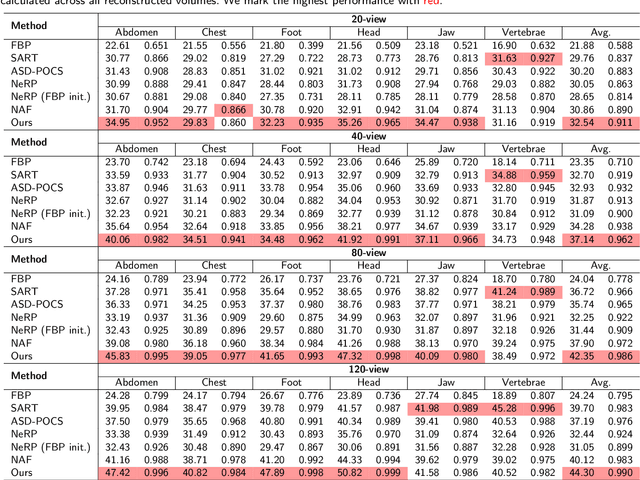
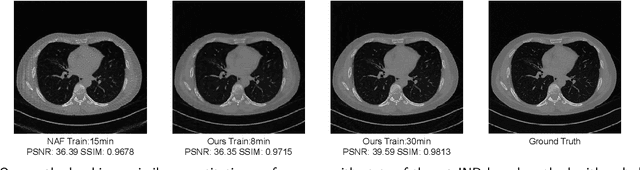

Sparse-view CT is a promising strategy for reducing the radiation dose of traditional CT scans, but reconstructing high-quality images from incomplete and noisy data is challenging. Recently, 3D Gaussian has been applied to model complex natural scenes, demonstrating fast convergence and better rendering of novel views compared to implicit neural representations (INRs). Taking inspiration from the successful application of 3D Gaussians in natural scene modeling and novel view synthesis, we investigate their potential for sparse-view CT reconstruction. We leverage prior information from the filtered-backprojection reconstructed image to initialize the Gaussians; and update their parameters via comparing difference in the projection space. Performance is further enhanced by adaptive density control. Compared to INRs, 3D Gaussians benefit more from prior information to explicitly bypass learning in void spaces and allocate the capacity efficiently, accelerating convergence. 3D Gaussians also efficiently learn high-frequency details. Trained in a self-supervised manner, 3D Gaussians avoid the need for large-scale paired data. Our experiments on the AAPM-Mayo dataset demonstrate that 3D Gaussians can provide superior performance compared to INR-based methods. This work is in progress, and the code will be publicly available.
LoCo: Locally Constrained Training-Free Layout-to-Image Synthesis
Nov 21, 2023Recent text-to-image diffusion models have reached an unprecedented level in generating high-quality images. However, their exclusive reliance on textual prompts often falls short in accurately conveying fine-grained spatial compositions. In this paper, we propose LoCo, a training-free approach for layout-to-image synthesis that excels in producing high-quality images aligned with both textual prompts and spatial layouts. Our method introduces a Localized Attention Constraint to refine cross-attention for individual objects, ensuring their precise placement in designated regions. We further propose a Padding Token Constraint to leverage the semantic information embedded in previously neglected padding tokens, thereby preventing the undesired fusion of synthesized objects. LoCo seamlessly integrates into existing text-to-image and layout-to-image models, significantly amplifying their performance and effectively addressing semantic failures observed in prior methods. Through extensive experiments, we showcase the superiority of our approach, surpassing existing state-of-the-art training-free layout-to-image methods both qualitatively and quantitatively across multiple benchmarks.
DiffULD: Diffusive Universal Lesion Detection
Mar 28, 2023Universal Lesion Detection (ULD) in computed tomography (CT) plays an essential role in computer-aided diagnosis. Promising ULD results have been reported by anchor-based detection designs, but they have inherent drawbacks due to the use of anchors: i) Insufficient training targets and ii) Difficulties in anchor design. Diffusion probability models (DPM) have demonstrated outstanding capabilities in many vision tasks. Many DPM-based approaches achieve great success in natural image object detection without using anchors. But they are still ineffective for ULD due to the insufficient training targets. In this paper, we propose a novel ULD method, DiffULD, which utilizes DPM for lesion detection. To tackle the negative effect triggered by insufficient targets, we introduce a novel center-aligned bounding box padding strategy that provides additional high-quality training targets yet avoids significant performance deterioration. DiffULD is inherently advanced in locating lesions with diverse sizes and shapes since it can predict with arbitrary boxes. Experiments on the benchmark dataset DeepLesion show the superiority of DiffULD when compared to state-of-the-art ULD approaches.