 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant Sampling for Improving Diffusion Model-based Image Restoration
Nov 13, 2025

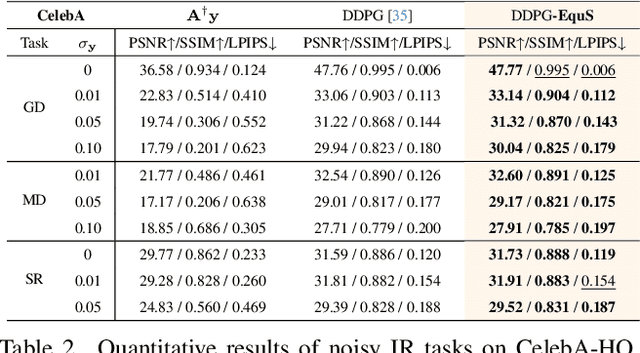

Recent advances in generative models, especially diffusion models, have significantly improved image restoration (IR) performance. However, existing problem-agnostic diffusion model-based image restoration (DMIR) methods face challenges in fully leveraging diffusion priors, resulting in suboptimal performance. In this paper, we address the limitations of current problem-agnostic DMIR methods by analyzing their sampling process and providing effective solutions. We introduce EquS, a DMIR method that imposes equivariant information through dual sampling trajectories. To further boost EquS, we propose the Timestep-Aware Schedule (TAS) and introduce EquS$^+$. TAS prioritizes deterministic steps to enhance certainty and sampling efficiency. Extensive experiments on benchmarks demonstrate that our method is compatible with previous problem-agnostic DMIR methods and significantly boosts their performance without increasing computational costs. Our code is available at https://github.com/FouierL/EquS.
U-RWKV: Lightweight medical image segmentation with direction-adaptive RWKV
Jul 15, 2025Achieving equity in healthcare accessibility requires lightweight yet high-performance solutions for medical image segmentation, particularly in resource-limited settings. Existing methods like U-Net and its variants often suffer from limited global Effective Receptive Fields (ERFs), hindering their ability to capture long-range dependencies. To address this, we propose U-RWKV, a novel framework leveraging the Recurrent Weighted Key-Value(RWKV) architecture, which achieves efficient long-range modeling at O(N) computational cost. The framework introduces two key innovations: the Direction-Adaptive RWKV Module(DARM) and the Stage-Adaptive Squeeze-and-Excitation Module(SASE). DARM employs Dual-RWKV and QuadScan mechanisms to aggregate contextual cues across images, mitigating directional bias while preserving global context and maintaining high computational efficiency. SASE dynamically adapts its architecture to different feature extraction stages, balancing high-resolution detail preservation and semantic relationship capture. Experiments demonstrate that U-RWKV achieves state-of-the-art segmentation performance with high computational efficiency, offering a practical solution for democratizing advanced medical imaging technologies in resource-constrained environments. The code is available at https://github.com/hbyecoding/U-RWKV.
LoCo: Locally Constrained Training-Free Layout-to-Image Synthesis
Nov 21, 2023Recent text-to-image diffusion models have reached an unprecedented level in generating high-quality images. However, their exclusive reliance on textual prompts often falls short in accurately conveying fine-grained spatial compositions. In this paper, we propose LoCo, a training-free approach for layout-to-image synthesis that excels in producing high-quality images aligned with both textual prompts and spatial layouts. Our method introduces a Localized Attention Constraint to refine cross-attention for individual objects, ensuring their precise placement in designated regions. We further propose a Padding Token Constraint to leverage the semantic information embedded in previously neglected padding tokens, thereby preventing the undesired fusion of synthesized objects. LoCo seamlessly integrates into existing text-to-image and layout-to-image models, significantly amplifying their performance and effectively addressing semantic failures observed in prior methods. Through extensive experiments, we showcase the superiority of our approach, surpassing existing state-of-the-art training-free layout-to-image methods both qualitatively and quantitatively across multiple benchmarks.
DiffULD: Diffusive Universal Lesion Detection
Mar 28, 2023Universal Lesion Detection (ULD) in computed tomography (CT) plays an essential role in computer-aided diagnosis. Promising ULD results have been reported by anchor-based detection designs, but they have inherent drawbacks due to the use of anchors: i) Insufficient training targets and ii) Difficulties in anchor design. Diffusion probability models (DPM) have demonstrated outstanding capabilities in many vision tasks. Many DPM-based approaches achieve great success in natural image object detection without using anchors. But they are still ineffective for ULD due to the insufficient training targets. In this paper, we propose a novel ULD method, DiffULD, which utilizes DPM for lesion detection. To tackle the negative effect triggered by insufficient targets, we introduce a novel center-aligned bounding box padding strategy that provides additional high-quality training targets yet avoids significant performance deterioration. DiffULD is inherently advanced in locating lesions with diverse sizes and shapes since it can predict with arbitrary boxes. Experiments on the benchmark dataset DeepLesion show the superiority of DiffULD when compared to state-of-the-art ULD approaches.