 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing Previously Undetectable Faults in Deep Neural Networks
Jun 01, 2021


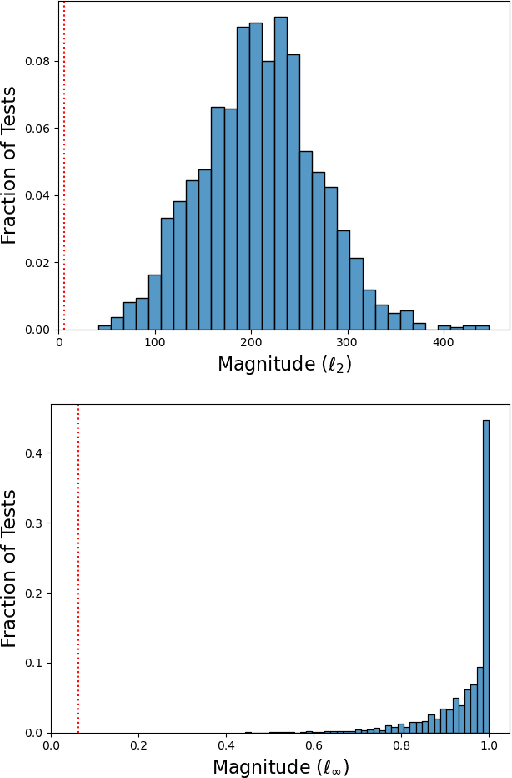
Existing methods for testing DNNs solve the oracle problem by constraining the raw features (e.g. image pixel values) to be within a small distance of a dataset example for which the desired DNN output is known. But this limits the kinds of faults these approaches are able to detect. In this paper, we introduce a novel DNN testing method that is able to find faults in DNNs that other methods cannot. The crux is that, by leveraging generative machine learning, we can generate fresh test inputs that vary in their high-level features (for images, these include object shape, location, texture, and colour). We demonstrate that our approach is capable of detecting deliberately injected faults as well as new faults in state-of-the-art DNNs, and that in both cases, existing methods are unable to find these faults.
Semantic Adversarial Perturbations using Learnt Representations
Jan 29, 2020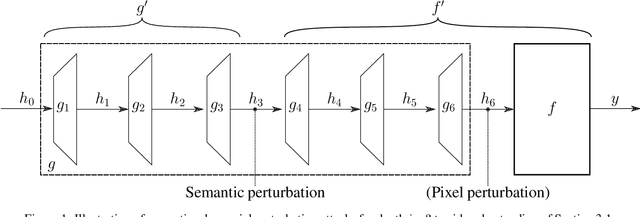
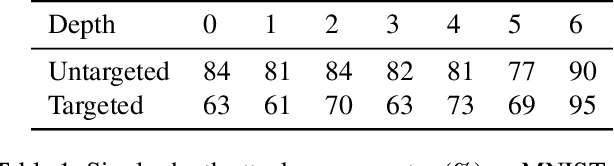
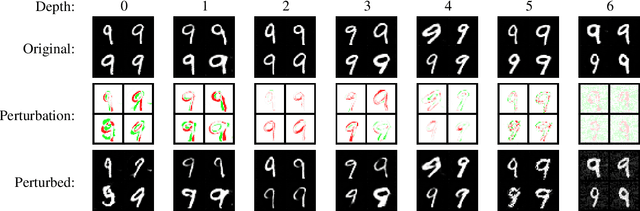
Adversarial examples for image classifiers are typically created by searching for a suitable norm-constrained perturbation to the pixels of an image. However, such perturbations represent only a small and rather contrived subset of possible adversarial inputs; robustness to norm-constrained pixel perturbations alone is insufficient. We introduce a novel method for the construction of a rich new class of semantic adversarial examples. Leveraging the hierarchical feature representations learnt by generative models, our procedure makes adversarial but realistic changes at different levels of semantic granularity. Unlike prior work, this is not an ad-hoc algorithm targeting a fixed category of semantic property. For instance, our approach perturbs the pose, location, size, shape, colour and texture of the objects in an image without manual encoding of these concepts. We demonstrate this new attack by creating semantic adversarial examples that fool state-of-the-art classifiers on the MNIST and ImageNet datasets.
Generating Realistic Unrestricted Adversarial Inputs using Dual-Objective GAN Training
May 07, 2019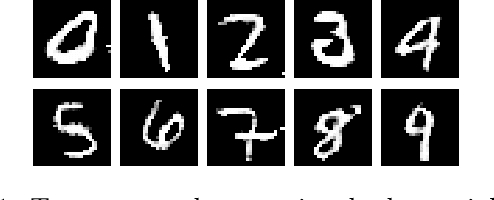

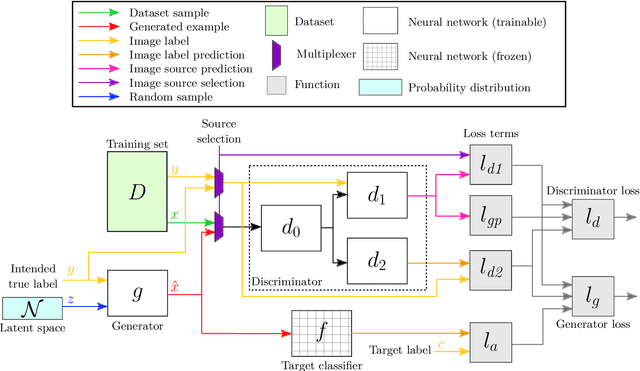

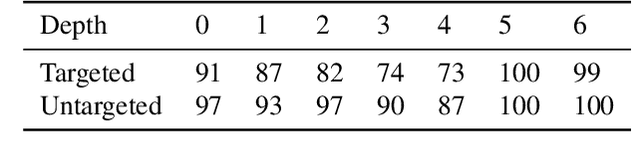
The correctness of deep neural networks is well-known to be vulnerable to small, 'adversarial' perturbations of their inputs. Although studying these attacks is valuable, they do not necessarily conform to any real-world threat model. This has led to interest in the generation of (and robustness to) unrestricted adversarial inputs, which are not constructed as small perturbations of correctly-classified ground-truth inputs. We introduce a novel algorithm to generate realistic unrestricted adversarial inputs, in the sense that they cannot reliably be distinguished from the training dataset by a human. This is achieved by modifying generative adversarial networks: a generator neural network is trained to construct examples that deceive a fixed target network (so they are adversarial) while also deceiving the usual co-training discriminator network (so they are realistic). Our approach is demonstrated by the generation of unrestricted adversarial inputs for a trained image classifier that is robust to perturbation-based attacks. We find that human judges are unable to identify which image out of ten was generated by our method about 50 percent of the time, providing evidence that they are moderately realistic.