 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Realistic Unrestricted Adversarial Inputs using Dual-Objective GAN Training
Paper and Code

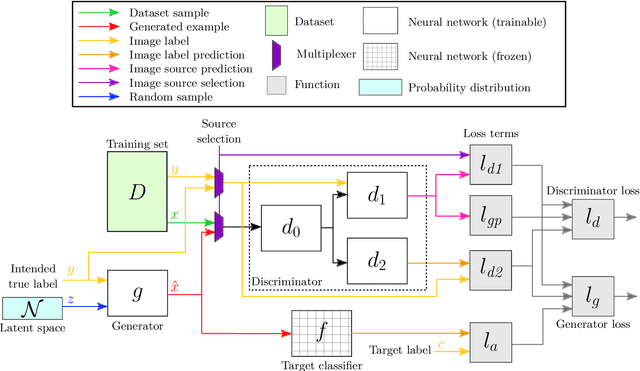

The correctness of deep neural networks is well-known to be vulnerable to small, 'adversarial' perturbations of their inputs. Although studying these attacks is valuable, they do not necessarily conform to any real-world threat model. This has led to interest in the generation of (and robustness to) unrestricted adversarial inputs, which are not constructed as small perturbations of correctly-classified ground-truth inputs. We introduce a novel algorithm to generate realistic unrestricted adversarial inputs, in the sense that they cannot reliably be distinguished from the training dataset by a human. This is achieved by modifying generative adversarial networks: a generator neural network is trained to construct examples that deceive a fixed target network (so they are adversarial) while also deceiving the usual co-training discriminator network (so they are realistic). Our approach is demonstrated by the generation of unrestricted adversarial inputs for a trained image classifier that is robust to perturbation-based attacks. We find that human judges are unable to identify which image out of ten was generated by our method about 50 percent of the time, providing evidence that they are moderately realistic.