 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShielding Atari Games with Bounded Prescience
Paper and Code
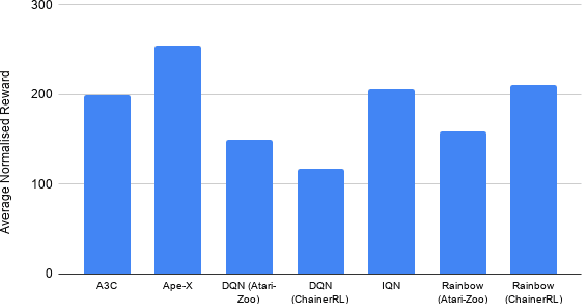
Deep reinforcement learning (DRL) is applied in safety-critical domains such as robotics and autonomous driving. It achieves superhuman abilities in many tasks, however whether DRL agents can be shown to act safely is an open problem. Atari games are a simple yet challenging exemplar for evaluating the safety of DRL agents and feature a diverse portfolio of game mechanics. The safety of neural agents has been studied before using methods that either require a model of the system dynamics or an abstraction; unfortunately, these are unsuitable to Atari games because their low-level dynamics are complex and hidden inside their emulator. We present the first exact method for analysing and ensuring the safety of DRL agents for Atari games. Our method only requires access to the emulator. First, we give a set of 43 properties that characterise "safe behaviour" for 30 games. Second, we develop a method for exploring all traces induced by an agent and a game and consider a variety of sources of game non-determinism. We observe that the best available DRL agents reliably satisfy only very few properties; several critical properties are violated by all agents. Finally, we propose a countermeasure that combines a bounded explicit-state exploration with shielding. We demonstrate that our method improves the safety of all agents over multiple properties.