 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogically-Constrained Reinforcement Learning
Paper and Code
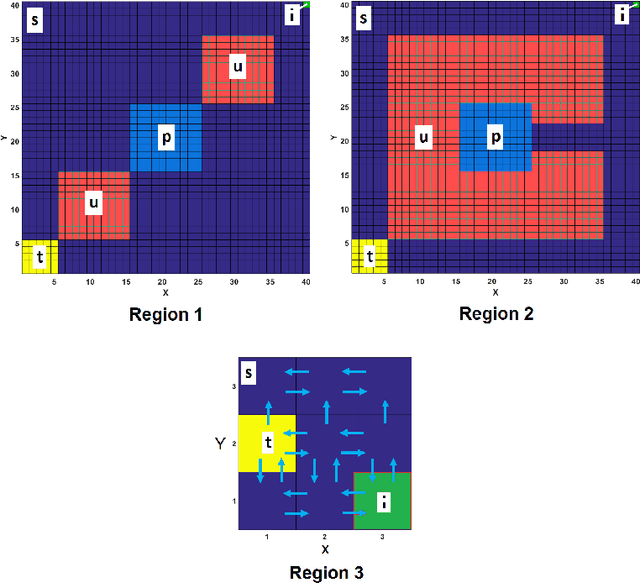


This paper proposes a model-free Reinforcement Learning (RL) algorithm to synthesise policies for an unknown Markov Decision Process (MDP), such that a linear time property is satisfied. We convert the given property into a Limit Deterministic Buchi Automaton (LDBA), then construct a synchronized MDP between the automaton and the original MDP. According to the resulting LDBA, a reward function is then defined over the state-action pairs of the product MDP. With this reward function, our algorithm synthesises a policy whose traces satisfies the linear time property: as such, the policy synthesis procedure is "constrained" by the given specification. Additionally, we show that the RL procedure sets up an online value iteration method to calculate the maximum probability of satisfying the given property, at any given state of the MDP - a convergence proof for the procedure is provided. Finally, the performance of the algorithm is evaluated via a set of numerical examples. We observe an improvement of one order of magnitude in the number of iterations required for the synthesis compared to existing approaches.