 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCautious Reinforcement Learning with Logical Constraints
Paper and Code
Mar 21, 2020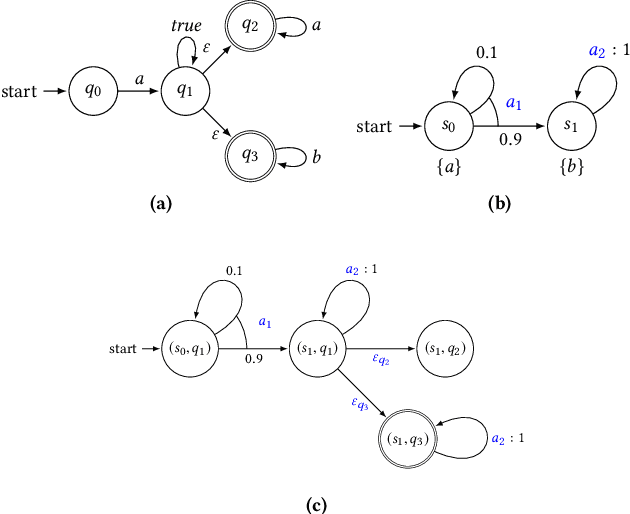
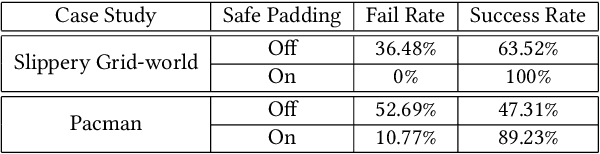
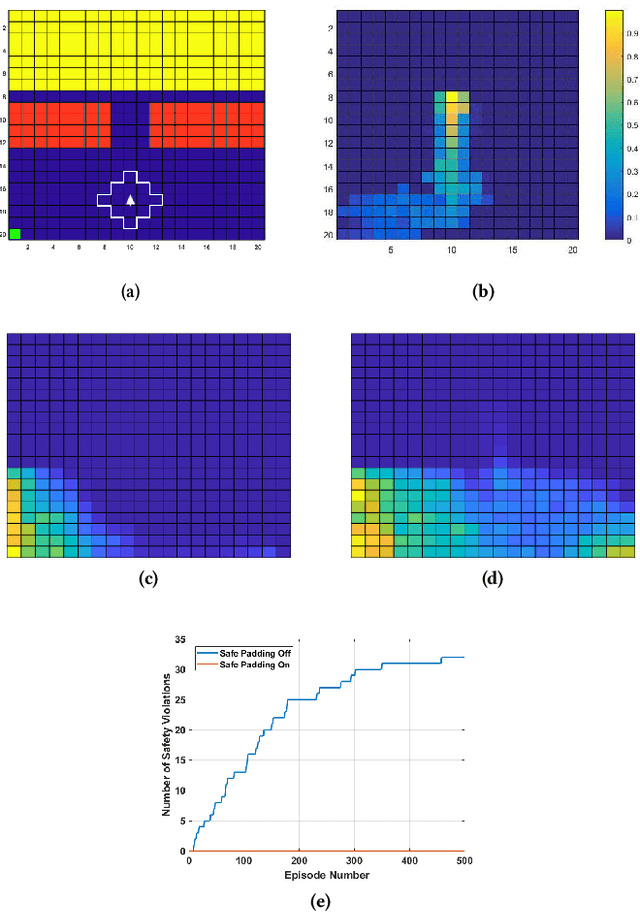
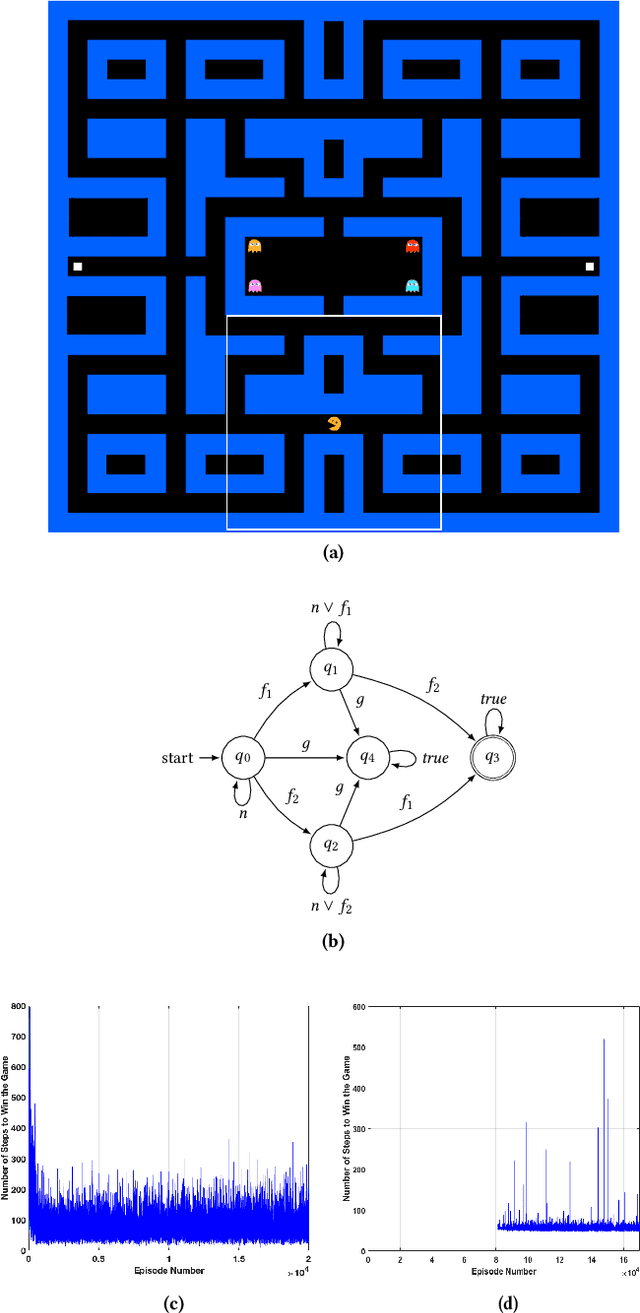
This paper presents the concept of an adaptive safe padding that forces Reinforcement Learning (RL) to synthesise optimal control policies while ensuring safety during the learning process. Policies are synthesised to satisfy a goal, expressed as a temporal logic formula, with maximal probability. Enforcing the RL agent to stay safe during learning might limit the exploration, however we show that the proposed architecture is able to automatically handle the trade-off between efficient progress in exploration (towards goal satisfaction) and ensuring safety. Theoretical guarantees are available on the optimality of the synthesised policies and on the convergence of the learning algorithm. Experimental results are provided to showcase the performance of the proposed method.