 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSynth: Program Synthesis for Automatic Task Segmentation in Deep Reinforcement Learning
Paper and Code
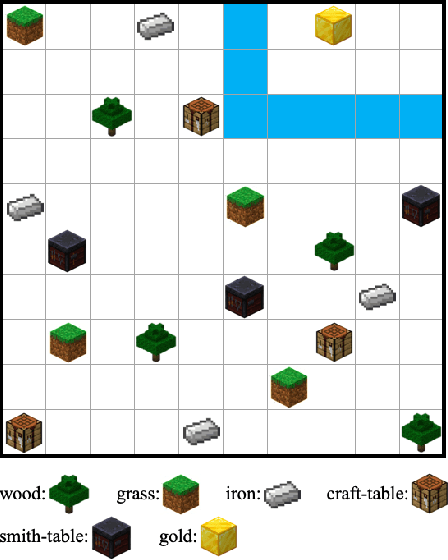
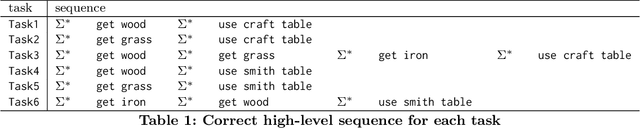
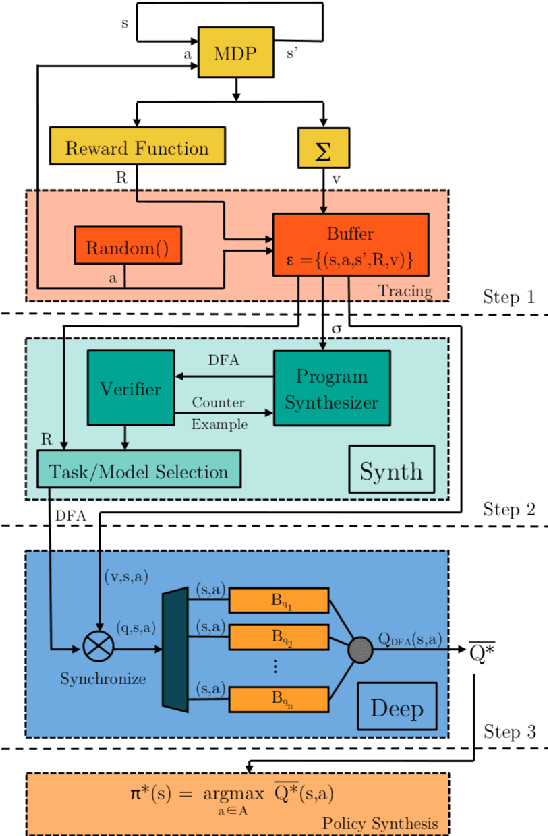
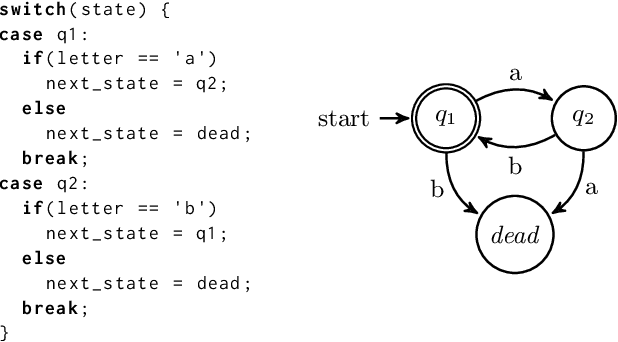
We propose a method for efficient training of deep Reinforcement Learning (RL) agents when the reward is highly sparse and non-Markovian, but at the same time admits a high-level yet unknown sequential structure, as seen in a number of video games. This high-level sequential structure can be expressed as a computer program, which our method infers automatically as the RL agent explores the environment. Through this process, a high-level sequential task that occurs only rarely may nonetheless be encoded within the inferred program. A hybrid architecture for deep neural fitted Q-iteration is then employed to fill in low-level details and generate an optimal control policy that follows the structure of the program. Our experiments show that the agent is able to synthesise a complex program to guide the RL exploitation phase, which is otherwise difficult to achieve with state-of-the-art RL techniques.