 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeprecating Benchmarks: Criteria and Framework
Jul 08, 2025As frontier artificial intelligence (AI) models rapidly advance, benchmarks are integral to comparing different models and measuring their progress in different task-specific domains. However, there is a lack of guidance on when and how benchmarks should be deprecated once they cease to effectively perform their purpose. This risks benchmark scores over-valuing model capabilities, or worse, obscuring capabilities and safety-washing. Based on a review of benchmarking practices, we propose criteria to decide when to fully or partially deprecate benchmarks, and a framework for deprecating benchmarks. Our work aims to advance the state of benchmarking towards rigorous and quality evaluations, especially for frontier models, and our recommendations are aimed to benefit benchmark developers, benchmark users, AI governance actors (across governments, academia, and industry panels), and policy makers.
Existing Industry Practice for the EU AI Act's General-Purpose AI Code of Practice Safety and Security Measures
Apr 21, 2025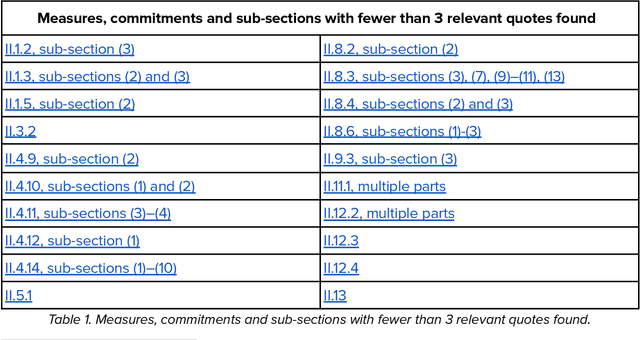
This report provides a detailed comparison between the measures proposed in the EU AI Act's General-Purpose AI (GPAI) Code of Practice (Third Draft) and current practices adopted by leading AI companies. As the EU moves toward enforcing binding obligations for GPAI model providers, the Code of Practice will be key to bridging legal requirements with concrete technical commitments. Our analysis focuses on the draft's Safety and Security section which is only relevant for the providers of the most advanced models (Commitments II.1-II.16) and excerpts from current public-facing documents quotes that are relevant to each individual measure. We systematically reviewed different document types - including companies' frontier safety frameworks and model cards - from over a dozen companies, including OpenAI, Anthropic, Google DeepMind, Microsoft, Meta, Amazon, and others. This report is not meant to be an indication of legal compliance nor does it take any prescriptive viewpoint about the Code of Practice or companies' policies. Instead, it aims to inform the ongoing dialogue between regulators and GPAI model providers by surfacing evidence of precedent.
VECHR: A Dataset for Explainable and Robust Classification of Vulnerability Type in the European Court of Human Rights
Oct 24, 2023Recognizing vulnerability is crucial for understanding and implementing targeted support to empower individuals in need. This is especially important at the European Court of Human Rights (ECtHR), where the court adapts Convention standards to meet actual individual needs and thus ensures effective human rights protection. However, the concept of vulnerability remains elusive at the ECtHR and no prior NLP research has dealt with it. To enable future research in this area, we present VECHR, a novel expert-annotated multi-label dataset comprising of vulnerability type classification and explanation rationale. We benchmark the performance of state-of-the-art models on VECHR from both prediction and explainability perspectives. Our results demonstrate the challenging nature of the task with lower prediction performance and limited agreement between models and experts. Further, we analyze the robustness of these models in dealing with out-of-domain (OOD) data and observe overall limited performance. Our dataset poses unique challenges offering significant room for improvement regarding performance, explainability, and robustness.