 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest arm identification in multi-armed bandits with delayed feedback
Mar 29, 2018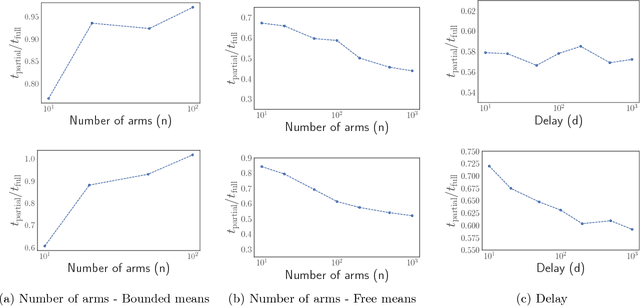
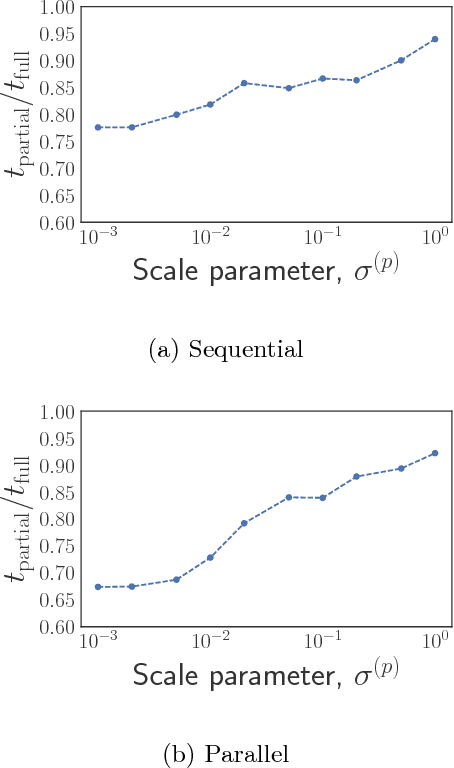
We propose a generalization of the best arm identification problem in stochastic multi-armed bandits (MAB) to the setting where every pull of an arm is associated with delayed feedback. The delay in feedback increases the effective sample complexity of standard algorithms, but can be offset if we have access to partial feedback received before a pull is completed. We propose a general framework to model the relationship between partial and delayed feedback, and as a special case we introduce efficient algorithms for settings where the partial feedback are biased or unbiased estimators of the delayed feedback. Additionally, we propose a novel extension of the algorithms to the parallel MAB setting where an agent can control a batch of arms. Our experiments in real-world settings, involving policy search and hyperparameter optimization in computational sustainability domains for fast charging of batteries and wildlife corridor construction, demonstrate that exploiting the structure of partial feedback can lead to significant improvements over baselines in both sequential and parallel MAB.