 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Similarity Drug-Target Interaction Prediction with Random Walks and Matrix Factorization
Jan 24, 2022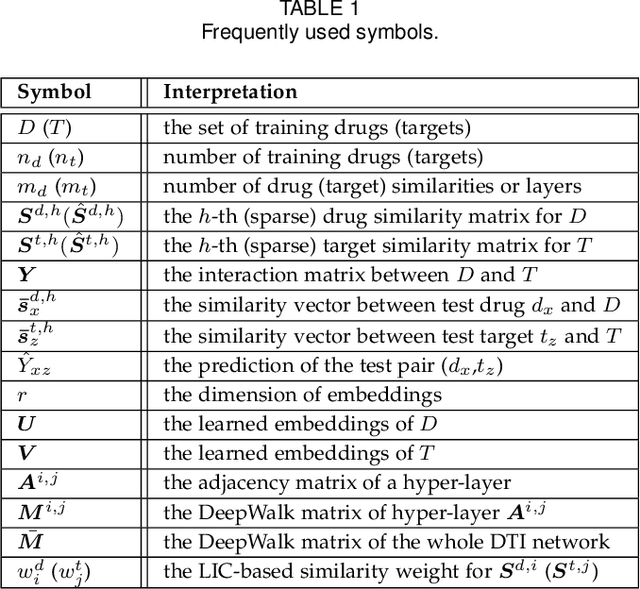

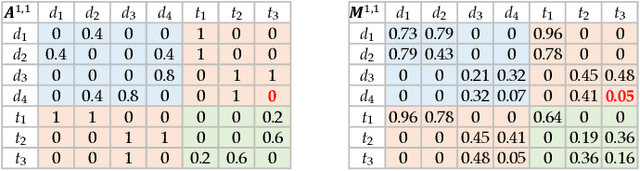
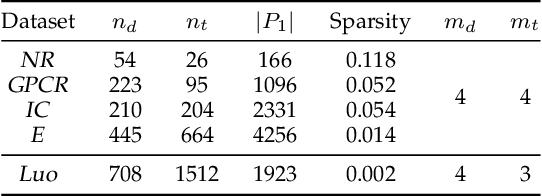
The discovery of drug-target interactions (DTIs) is a very promising area of research with great potential. In general, the identification of reliable interactions among drugs and proteins can boost the development of effective pharmaceuticals. In this work, we leverage random walks and matrix factorization techniques towards DTI prediction. In particular, we take a multi-layered network perspective, where different layers correspond to different similarity metrics between drugs and targets. To fully take advantage of topology information captured in multiple views, we develop an optimization framework, called MDMF, for DTI prediction. The framework learns vector representations of drugs and targets that not only retain higher-order proximity across all hyper-layers and layer-specific local invariance, but also approximates the interactions with their inner product. Furthermore, we propose an ensemble method, called MDMF2A, which integrates two instantiations of the MDMF model that optimize surrogate losses of the area under the precision-recall curve (AUPR) and the area under the receiver operating characteristic curve (AUC), respectively. The empirical study on real-world DTI datasets shows that our method achieves significant improvement over current state-of-the-art approaches in four different settings. Moreover, the validation of highly ranked non-interacting pairs also demonstrates the potential of MDMF2A to discover novel DTIs.
${\rm N{\small ode}S{\small ig}}$: Random Walk Diffusion meets Hashing for Scalable Graph Embeddings
Oct 01, 2020
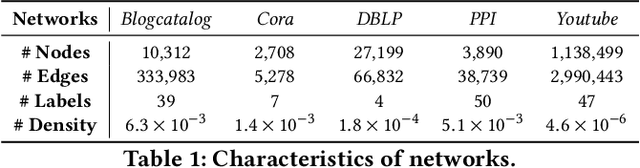
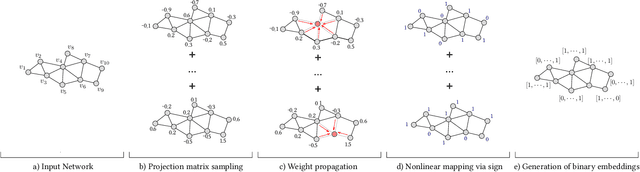
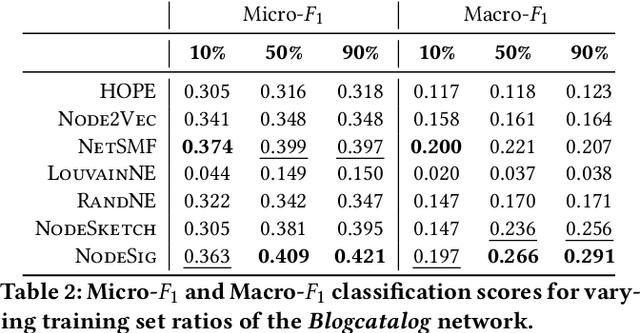
Learning node representations is a crucial task with a plethora of interdisciplinary applications. Nevertheless, as the size of the networks increases, most widely used models face computational challenges to scale to large networks. While there is a recent effort towards designing algorithms that solely deal with scalability issues, most of them behave poorly in terms of accuracy on downstream tasks. In this paper, we aim at studying models that balance the trade-off between efficiency and accuracy. In particular, we propose ${\rm N{\small ode}S{\small ig}}$, a scalable embedding model that computes binary node representations. ${\rm N{\small ode}S{\small ig}}$ exploits random walk diffusion probabilities via stable random projection hashing, towards efficiently computing embeddings in the Hamming space. Our extensive experimental evaluation on various graphs has demonstrated that the proposed model achieves a good balance between accuracy and efficiency compared to well-known baseline models on two downstream tasks.
Keywords lie far from the mean of all words in local vector space
Aug 21, 2020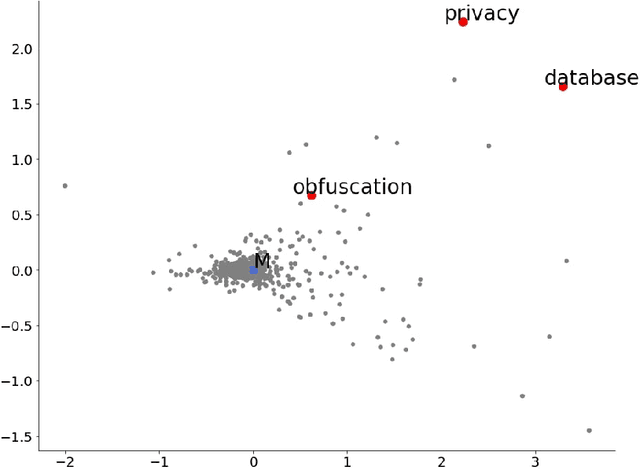
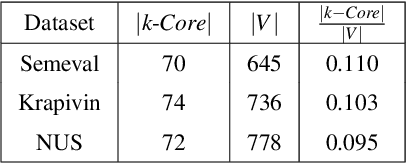

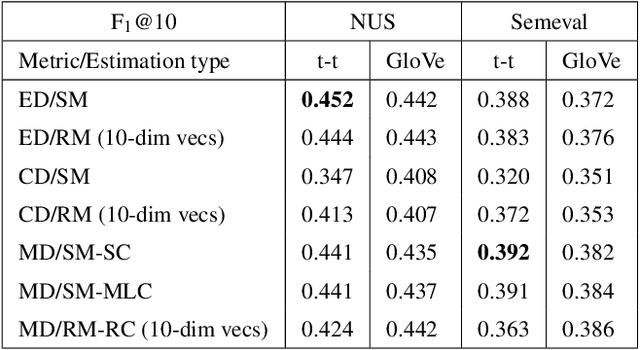
Keyword extraction is an important document process that aims at finding a small set of terms that concisely describe a document's topics. The most popular state-of-the-art unsupervised approaches belong to the family of the graph-based methods that build a graph-of-words and use various centrality measures to score the nodes (candidate keywords). In this work, we follow a different path to detect the keywords from a text document by modeling the main distribution of the document's words using local word vector representations. Then, we rank the candidates based on their position in the text and the distance between the corresponding local vectors and the main distribution's center. We confirm the high performance of our approach compared to strong baselines and state-of-the-art unsupervised keyword extraction methods, through an extended experimental study, investigating the properties of the local representations.
RELINE: Point-of-Interest Recommendations using Multiple Network Embeddings
Feb 02, 2019

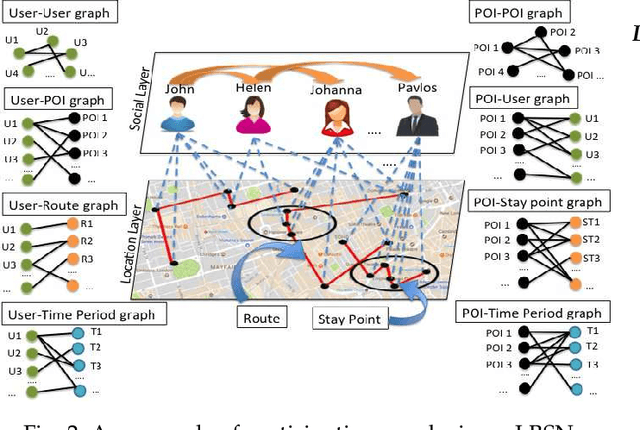

The rapid growth of users' involvement in Location-Based Social Networks (LBSNs) has led to the expeditious growth of the data on a global scale. The need of accessing and retrieving relevant information close to users' preferences is an open problem which continuously raises new challenges for recommendation systems. The exploitation of Points-of-Interest (POIs) recommendation by existing models is inadequate due to the sparsity and the cold start problems. To overcome these problems many models were proposed in the literature, but most of them ignore important factors such as: geographical proximity, social influence, or temporal and preference dynamics, which tackle their accuracy while personalize their recommendations. In this work, we investigate these problems and present a unified model that jointly learns users and POI dynamics. Our proposal is termed RELINE (REcommendations with muLtIple Network Embeddings). More specifically, RELINE captures: i) the social, ii) the geographical, iii) the temporal influence, and iv) the users' preference dynamics, by embedding eight relational graphs into one shared latent space. We have evaluated our approach against state-of-the-art methods with three large real-world datasets in terms of accuracy. Additionally, we have examined the effectiveness of our approach against the cold-start problem. Performance evaluation results demonstrate that significant performance improvement is achieved in comparison to existing state-of-the-art methods.