 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGATA2Floor: Graph attention for floor counting in street-view facades
May 12, 2026Automated analysis of building facades from street-level imagery has great potential for urban analytics, energy assessment, and emergency planning. However, it requires reasoning over spatially arranged elements rather than solely isolated detections. In this work, we model each facade as a graph over window/door detections with a vertical prior on edges. Additionally, we introduce GATA2Floor, a multi-head Graph Attention v2 (GATv2) based model that predicts the global floor count of a building and, via learnable cross-attention queries, softly assigns elements to latent floor slots, yielding interpretable outputs and robustness to irregular designs. To mitigate the lack of labeled datasets, we demonstrate that the proposed graph-based reasoning can be applied without annotations by leveraging a lightweight label-free proposal mechanism based on self-supervised features and vision-language scoring. Our approach demonstrates the value of graph-attention-based relational reasoning for facade understanding.
Keywords lie far from the mean of all words in local vector space
Aug 21, 2020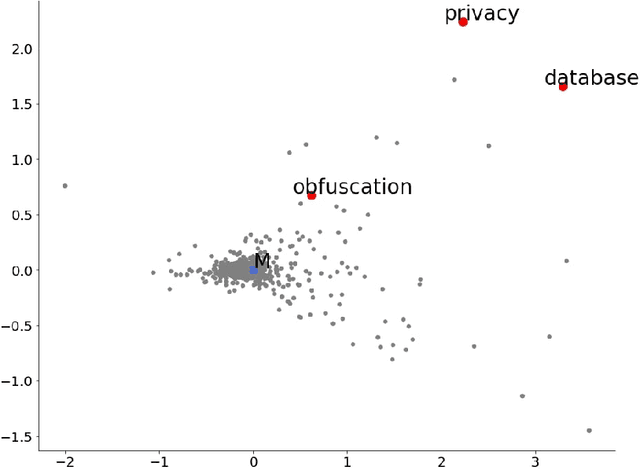

Keyword extraction is an important document process that aims at finding a small set of terms that concisely describe a document's topics. The most popular state-of-the-art unsupervised approaches belong to the family of the graph-based methods that build a graph-of-words and use various centrality measures to score the nodes (candidate keywords). In this work, we follow a different path to detect the keywords from a text document by modeling the main distribution of the document's words using local word vector representations. Then, we rank the candidates based on their position in the text and the distance between the corresponding local vectors and the main distribution's center. We confirm the high performance of our approach compared to strong baselines and state-of-the-art unsupervised keyword extraction methods, through an extended experimental study, investigating the properties of the local representations.
A Review of Keyphrase Extraction
May 13, 2019



Automated keyphrase extraction is a crucial textual information processing task regarding the most types of digital content management systems. It concerns the selection of representative and characteristic phrases from a document that express all aspects related to its content. This article introduces the task of keyphrase extraction and provides a view of existing work that is well organized and comprehensive. Moreover, it discusses the different evaluation approaches giving meaningful insights and highlighting open issues. Finally, a comparative experimental study for popular unsupervised techniques on five datasets is presented.
Unsupervised Keyphrase Extraction Based on Outlier Detection
Aug 10, 2018



We propose a novel unsupervised keyphrase extraction approach based on outlier detection. Our approach starts by training word embeddings on the target document to capture semantic regularities among the words. It then uses the minimum covariance determinant estimator to model the distribution of non-keyphrase word vectors, under the assumption that these vectors come from the same distribution, indicative of their irrelevance to the semantics expresses by the dimensions of the learned vector representation. Candidate keyphrases are based on words that are outliers of this dominant distribution. Empirical results show that our approach outperforms state-of-the-art unsupervised keyphrase extraction methods.
Local Word Vectors Guiding Keyphrase Extraction
Apr 13, 2018



Automated keyphrase extraction is a fundamental textual information processing task concerned with the selection of representative phrases from a document that summarize its content. This work presents a novel unsupervised method for keyphrase extraction, whose main innovation is the use of local word embeddings (in particular GloVe vectors), i.e., embeddings trained from the single document under consideration. We argue that such local representation of words and keyphrases are able to accurately capture their semantics in the context of the document they are part of, and therefore can help in improving keyphrase extraction quality. Empirical results offer evidence that indeed local representations lead to better keyphrase extraction results compared to both embeddings trained on very large third corpora or larger corpora consisting of several documents of the same scientific field and to other state-of-the-art unsupervised keyphrase extraction methods.