 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Semantic Segmentation with Fast Attention
Paper and Code
Jul 09, 2020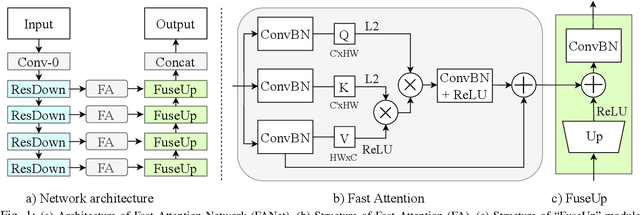
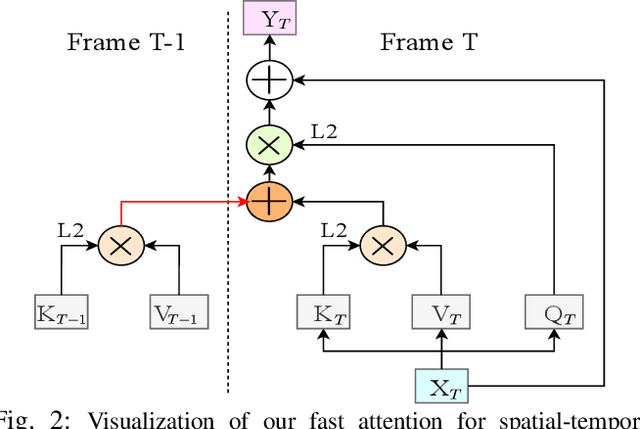
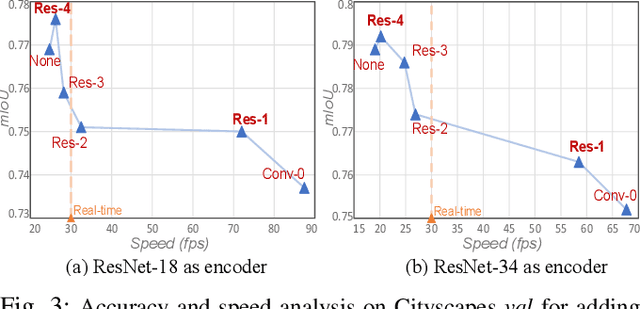

In deep CNN based models for semantic segmentation, high accuracy relies on rich spatial context (large receptive fields) and fine spatial details (high resolution), both of which incur high computational costs. In this paper, we propose a novel architecture that addresses both challenges and achieves state-of-the-art performance for semantic segmentation of high-resolution images and videos in real-time. The proposed architecture relies on our fast spatial attention, which is a simple yet efficient modification of the popular self-attention mechanism and captures the same rich spatial context at a small fraction of the computational cost, by changing the order of operations. Moreover, to efficiently process high-resolution input, we apply an additional spatial reduction to intermediate feature stages of the network with minimal loss in accuracy thanks to the use of the fast attention module to fuse features. We validate our method with a series of experiments, and show that results on multiple datasets demonstrate superior performance with better accuracy and speed compared to existing approaches for real-time semantic segmentation. On Cityscapes, our network achieves 74.4$\%$ mIoU at 72 FPS and 75.5$\%$ mIoU at 58 FPS on a single Titan X GPU, which is~$\sim$50$\%$ faster than the state-of-the-art while retaining the same accuracy.