Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Deep Representations for Learning Audience Facial Behaviors
Paper and Code
May 10, 2018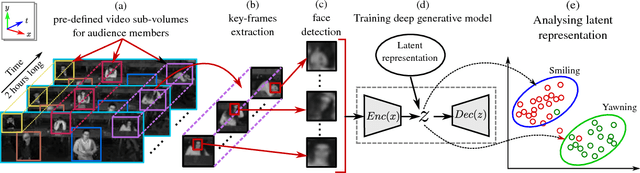
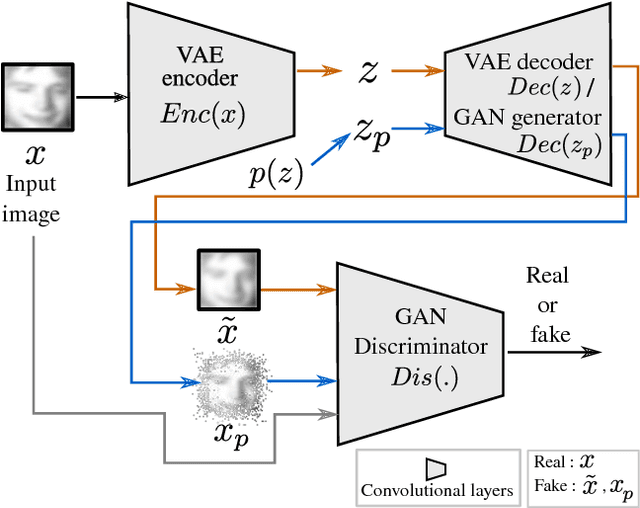

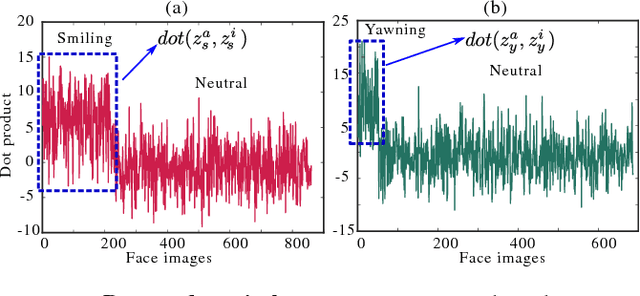
In this paper, we present an unsupervised learning approach for analyzing facial behavior based on a deep generative model combined with a convolutional neural network (CNN). We jointly train a variational auto-encoder (VAE) and a generative adversarial network (GAN) to learn a powerful latent representation from footage of audiences viewing feature-length movies. We show that the learned latent representation successfully encodes meaningful signatures of behaviors related to audience engagement (smiling & laughing) and disengagement (yawning). Our results provide a proof of concept for a more general methodology for annotating hard-to-label multimedia data featuring sparse examples of signals of interest.
View paper on