 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution Matching via Generalized Consistency Models
Aug 17, 2025Recent advancement in generative models have demonstrated remarkable performance across various data modalities. Beyond their typical use in data synthesis, these models play a crucial role in distribution matching tasks such as latent variable modeling, domain translation, and domain adaptation. Generative Adversarial Networks (GANs) have emerged as the preferred method of distribution matching due to their efficacy in handling high-dimensional data and their flexibility in accommodating various constraints. However, GANs often encounter challenge in training due to their bi-level min-max optimization objective and susceptibility to mode collapse. In this work, we propose a novel approach for distribution matching inspired by the consistency models employed in Continuous Normalizing Flow (CNF). Our model inherits the advantages of CNF models, such as having a straight forward norm minimization objective, while remaining adaptable to different constraints similar to GANs. We provide theoretical validation of our proposed objective and demonstrate its performance through experiments on synthetic and real-world datasets.
Domain-Factored Untrained Deep Prior for Spectrum Cartography
Jan 23, 2025Spectrum cartography (SC) focuses on estimating the radio power propagation map of multiple emitters across space and frequency using limited sensor measurements. Recent advances in SC have shown that leveraging learned deep generative models (DGMs) as structural constraints yields state-of-the-art performance. By harnessing the expressive power of neural networks, these structural "priors" capture intricate patterns in radio maps. However, training DGMs requires substantial data, which is not always available, and distribution shifts between training and testing data can further degrade performance. To address these challenges, this work proposes using untrained neural networks (UNNs) for SC. UNNs, commonly applied in vision tasks to represent complex data without training, encode structural information of data in neural architectures. In our approach, a custom-designed UNN represents radio maps under a spatio-spectral domain factorization model, leveraging physical characteristics to reduce sample complexity of SC. Experiments show that the method achieves performance comparable to learned DGM-based SC, without requiring training data.
Identifiable Shared Component Analysis of Unpaired Multimodal Mixtures
Sep 28, 2024A core task in multi-modal learning is to integrate information from multiple feature spaces (e.g., text and audio), offering modality-invariant essential representations of data. Recent research showed that, classical tools such as {\it canonical correlation analysis} (CCA) provably identify the shared components up to minor ambiguities, when samples in each modality are generated from a linear mixture of shared and private components. Such identifiability results were obtained under the condition that the cross-modality samples are aligned/paired according to their shared information. This work takes a step further, investigating shared component identifiability from multi-modal linear mixtures where cross-modality samples are unaligned. A distribution divergence minimization-based loss is proposed, under which a suite of sufficient conditions ensuring identifiability of the shared components are derived. Our conditions are based on cross-modality distribution discrepancy characterization and density-preserving transform removal, which are much milder than existing studies relying on independent component analysis. More relaxed conditions are also provided via adding reasonable structural constraints, motivated by available side information in various applications. The identifiability claims are thoroughly validated using synthetic and real-world data.
Quantized Radio Map Estimation Using Tensor and Deep Generative Models
Mar 03, 2023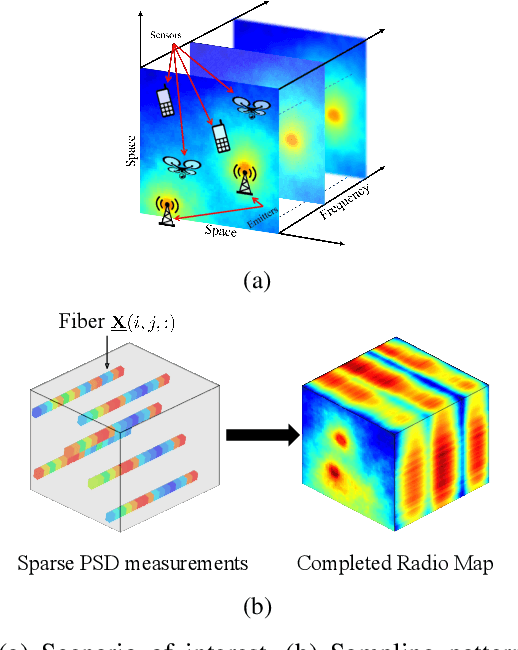
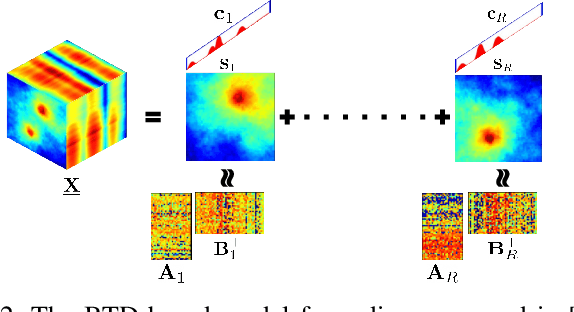
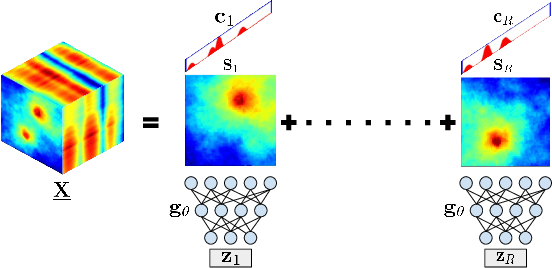
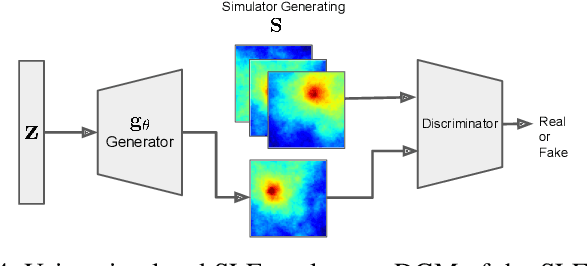
Spectrum cartography (SC), also known as radio map estimation (RME), aims at crafting multi-domain (e.g., frequency and space) radio power propagation maps from limited sensor measurements. While early methods often lacked theoretical support, recent works have demonstrated that radio maps can be provably recovered using low-dimensional models -- such as the block-term tensor decomposition (BTD) model and certain deep generative models (DGMs) -- of the high-dimensional multi-domain radio signals. However, these existing provable SC approaches assume that sensors send real-valued (full-resolution) measurements to the fusion center, which is unrealistic. This work puts forth a quantized SC framework that generalizes the BTD and DGM-based SC to scenarios where heavily quantized sensor measurements are used. A maximum likelihood estimation (MLE)-based SC framework under a Gaussian quantizer is proposed. Recoverability of the radio map using the MLE criterion are characterized under realistic conditions, e.g., imperfect radio map modeling and noisy measurements. Simulations and real-data experiments are used to showcase the effectiveness of the proposed approach.
Search Disaster Victims using Sound Source Localization
Mar 10, 2021



Sound Source Localization (SSL) are used to estimate the position of sound sources. Various methods have been used for detecting sound and its localization. This paper presents a system for stationary sound source localization by cubical microphone array consisting of eight microphones placed on four vertical adjacent faces which is mounted on three wheel omni-directional drive for the inspection and monitoring of the disaster victims in disaster areas. The proposed method localizes sound source on a 3D space by grid search method using Generalized Cross Correlation Phase Transform (GCC-PHAT) which is robust when operating in real life scenario where there is lack of visibility. The computed azimuth and elevation angle of victimized human voice are fed to embedded omni-directional drive system which navigates the vehicle automatically towards the stationary sound source.
* 9 pages, 17 figures, 17th ISCRAM Conference Blacksburg, VA, USA