 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVID-19-related Nepali Tweets Classification in a Low Resource Setting
Oct 11, 2022


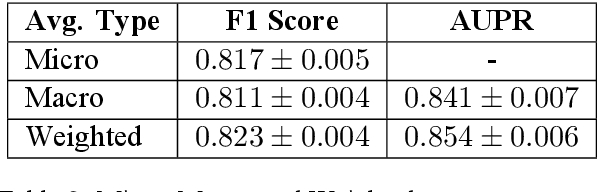
Billions of people across the globe have been using social media platforms in their local languages to voice their opinions about the various topics related to the COVID-19 pandemic. Several organizations, including the World Health Organization, have developed automated social media analysis tools that classify COVID-19-related tweets into various topics. However, these tools that help combat the pandemic are limited to very few languages, making several countries unable to take their benefit. While multi-lingual or low-resource language-specific tools are being developed, they still need to expand their coverage, such as for the Nepali language. In this paper, we identify the eight most common COVID-19 discussion topics among the Twitter community using the Nepali language, set up an online platform to automatically gather Nepali tweets containing the COVID-19-related keywords, classify the tweets into the eight topics, and visualize the results across the period in a web-based dashboard. We compare the performance of two state-of-the-art multi-lingual language models for Nepali tweet classification, one generic (mBERT) and the other Nepali language family-specific model (MuRIL). Our results show that the models' relative performance depends on the data size, with MuRIL doing better for a larger dataset. The annotated data, models, and the web-based dashboard are open-sourced at https://github.com/naamiinepal/covid-tweet-classification.
Search Disaster Victims using Sound Source Localization
Mar 10, 2021



Sound Source Localization (SSL) are used to estimate the position of sound sources. Various methods have been used for detecting sound and its localization. This paper presents a system for stationary sound source localization by cubical microphone array consisting of eight microphones placed on four vertical adjacent faces which is mounted on three wheel omni-directional drive for the inspection and monitoring of the disaster victims in disaster areas. The proposed method localizes sound source on a 3D space by grid search method using Generalized Cross Correlation Phase Transform (GCC-PHAT) which is robust when operating in real life scenario where there is lack of visibility. The computed azimuth and elevation angle of victimized human voice are fed to embedded omni-directional drive system which navigates the vehicle automatically towards the stationary sound source.
* 9 pages, 17 figures, 17th ISCRAM Conference Blacksburg, VA, USA
A Nepali Rule Based Stemmer and its performance on different NLP applications
Feb 23, 2020



Stemming is an integral part of Natural Language Processing (NLP). It's a preprocessing step in almost every NLP application. Arguably, the most important usage of stemming is in Information Retrieval (IR). While there are lots of work done on stemming in languages like English, Nepali stemming has only a few works. This study focuses on creating a Rule Based stemmer for Nepali text. Specifically, it is an affix stripping system that identifies two different class of suffixes in Nepali grammar and strips them separately. Only a single negativity prefix (Na) is identified and stripped. This study focuses on a number of techniques like exception word identification, morphological normalization and word transformation to increase stemming performance. The stemmer is tested intrinsically using Paice's method and extrinsically on a basic tf-idf based IR system and an elementary news topic classifier using Multinomial Naive Bayes Classifier. The difference in performance of these systems with and without using the stemmer is analysed.
* 5 pages, 2 figures, 3 tables