 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyStory: Towards Unified Single and Multiple Subject Personalization in Text-to-Image Generation
Jan 16, 2025Recently, large-scale generative models have demonstrated outstanding text-to-image generation capabilities. However, generating high-fidelity personalized images with specific subjects still presents challenges, especially in cases involving multiple subjects. In this paper, we propose AnyStory, a unified approach for personalized subject generation. AnyStory not only achieves high-fidelity personalization for single subjects, but also for multiple subjects, without sacrificing subject fidelity. Specifically, AnyStory models the subject personalization problem in an "encode-then-route" manner. In the encoding step, AnyStory utilizes a universal and powerful image encoder, i.e., ReferenceNet, in conjunction with CLIP vision encoder to achieve high-fidelity encoding of subject features. In the routing step, AnyStory utilizes a decoupled instance-aware subject router to accurately perceive and predict the potential location of the corresponding subject in the latent space, and guide the injection of subject conditions. Detailed experimental results demonstrate the excellent performance of our method in retaining subject details, aligning text descriptions, and personalizing for multiple subjects. The project page is at https://aigcdesigngroup.github.io/AnyStory/ .
AnyText2: Visual Text Generation and Editing With Customizable Attributes
Nov 22, 2024

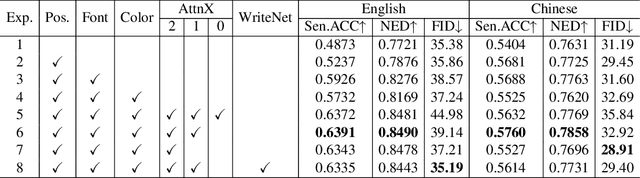

As the text-to-image (T2I) domain progresses, generating text that seamlessly integrates with visual content has garnered significant attention. However, even with accurate text generation, the inability to control font and color can greatly limit certain applications, and this issue remains insufficiently addressed. This paper introduces AnyText2, a novel method that enables precise control over multilingual text attributes in natural scene image generation and editing. Our approach consists of two main components. First, we propose a WriteNet+AttnX architecture that injects text rendering capabilities into a pre-trained T2I model. Compared to its predecessor, AnyText, our new approach not only enhances image realism but also achieves a 19.8% increase in inference speed. Second, we explore techniques for extracting fonts and colors from scene images and develop a Text Embedding Module that encodes these text attributes separately as conditions. As an extension of AnyText, this method allows for customization of attributes for each line of text, leading to improvements of 3.3% and 9.3% in text accuracy for Chinese and English, respectively. Through comprehensive experiments, we demonstrate the state-of-the-art performance of our method. The code and model will be made open-source in https://github.com/tyxsspa/AnyText2.
AnyText: Multilingual Visual Text Generation And Editing
Nov 07, 2023



Diffusion model based Text-to-Image has achieved impressive achievements recently. Although current technology for synthesizing images is highly advanced and capable of generating images with high fidelity, it is still possible to give the show away when focusing on the text area in the generated image. To address this issue, we introduce AnyText, a diffusion-based multilingual visual text generation and editing model, that focuses on rendering accurate and coherent text in the image. AnyText comprises a diffusion pipeline with two primary elements: an auxiliary latent module and a text embedding module. The former uses inputs like text glyph, position, and masked image to generate latent features for text generation or editing. The latter employs an OCR model for encoding stroke data as embeddings, which blend with image caption embeddings from the tokenizer to generate texts that seamlessly integrate with the background. We employed text-control diffusion loss and text perceptual loss for training to further enhance writing accuracy. AnyText can write characters in multiple languages, to the best of our knowledge, this is the first work to address multilingual visual text generation. It is worth mentioning that AnyText can be plugged into existing diffusion models from the community for rendering or editing text accurately. After conducting extensive evaluation experiments, our method has outperformed all other approaches by a significant margin. Additionally, we contribute the first large-scale multilingual text images dataset, AnyWord-3M, containing 3 million image-text pairs with OCR annotations in multiple languages. Based on AnyWord-3M dataset, we propose AnyText-benchmark for the evaluation of visual text generation accuracy and quality. Our project will be open-sourced on https://github.com/tyxsspa/AnyText to improve and promote the development of text generation technology.