 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Accent Modeling with Disentangling for Multi-Speaker Multi-Accent TTS Synthesis
Jun 16, 2024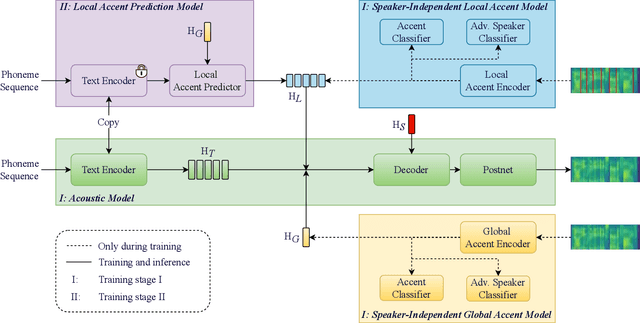
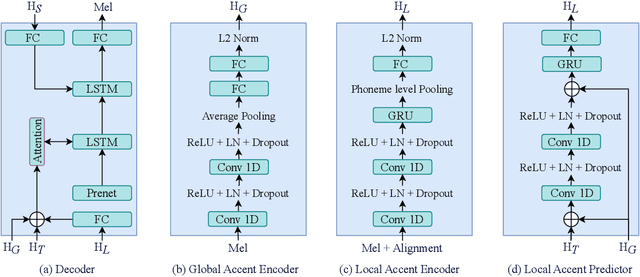
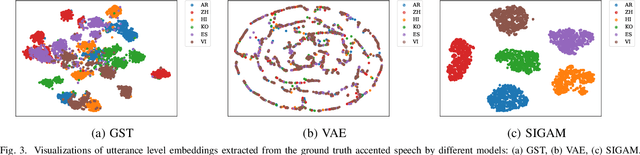
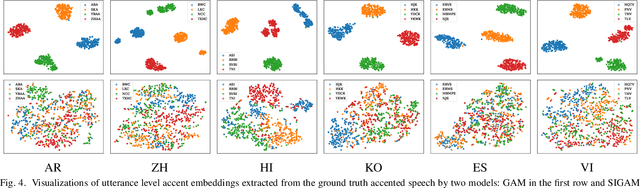
Synthesizing speech across different accents while preserving the speaker identity is essential for various real-world customer applications. However, the individual and accurate modeling of accents and speakers in a text-to-speech (TTS) system is challenging due to the complexity of accent variations and the intrinsic entanglement between the accent and speaker identity. In this paper, we present a novel approach for multi-speaker multi-accent TTS synthesis, which aims to synthesize voices of multiple speakers, each with various accents. Our proposed approach employs a multi-scale accent modeling strategy to address accent variations at different levels. Specifically, we introduce both global (utterance level) and local (phoneme level) accent modeling, supervised by individual accent classifiers to capture the overall variation within accented utterances and fine-grained variations between phonemes, respectively. To control accents and speakers separately, speaker-independent accent modeling is necessary, which is achieved by adversarial training with speaker classifiers to disentangle speaker identity within the multi-scale accent modeling. Consequently, we obtain speaker-independent and accent-discriminative multi-scale embeddings as comprehensive accent features. Additionally, we propose a local accent prediction model that allows to generate accented speech directly from phoneme inputs. Extensive experiments are conducted on an accented English speech corpus. Both objective and subjective evaluations show the superiority of our proposed system compared to baselines systems. Detailed component analysis demonstrates the effectiveness of global and local accent modeling, and speaker disentanglement on multi-speaker multi-accent speech synthesis.
Accented Text-to-Speech Synthesis with Limited Data
May 08, 2023
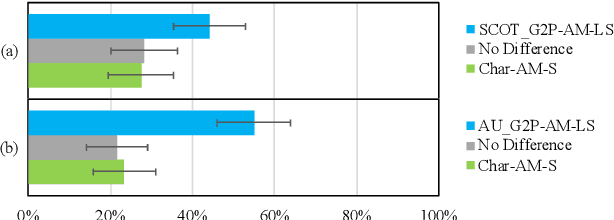
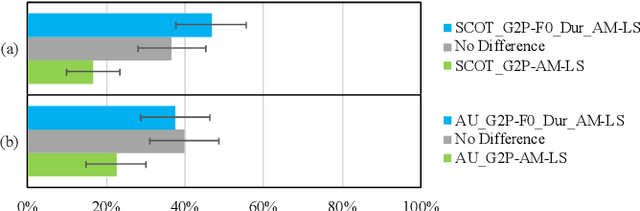
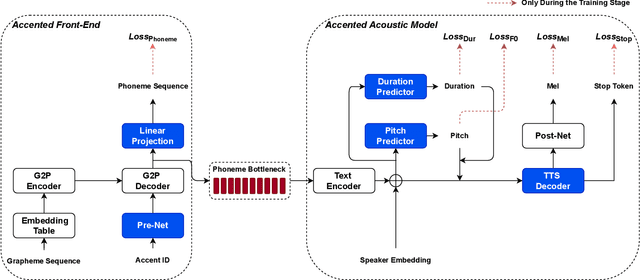
This paper presents an accented text-to-speech (TTS) synthesis framework with limited training data. We study two aspects concerning accent rendering: phonetic (phoneme difference) and prosodic (pitch pattern and phoneme duration) variations. The proposed accented TTS framework consists of two models: an accented front-end for grapheme-to-phoneme (G2P) conversion and an accented acoustic model with integrated pitch and duration predictors for phoneme-to-Mel-spectrogram prediction. The accented front-end directly models the phonetic variation, while the accented acoustic model explicitly controls the prosodic variation. Specifically, both models are first pre-trained on a large amount of data, then only the accent-related layers are fine-tuned on a limited amount of data for the target accent. In the experiments, speech data of three English accents, i.e., General American English, Irish English, and British English Received Pronunciation, are used for pre-training. The pre-trained models are then fine-tuned with Scottish and General Australian English accents, respectively. Both objective and subjective evaluation results show that the accented TTS front-end fine-tuned with a small accented phonetic lexicon (5k words) effectively handles the phonetic variation of accents, while the accented TTS acoustic model fine-tuned with a limited amount of accented speech data (approximately 3 minutes) effectively improves the prosodic rendering including pitch and duration. The overall accent modeling contributes to improved speech quality and accent similarity.
Exploring Teacher-Student Learning Approach for Multi-lingual Speech-to-Intent Classification
Sep 28, 2021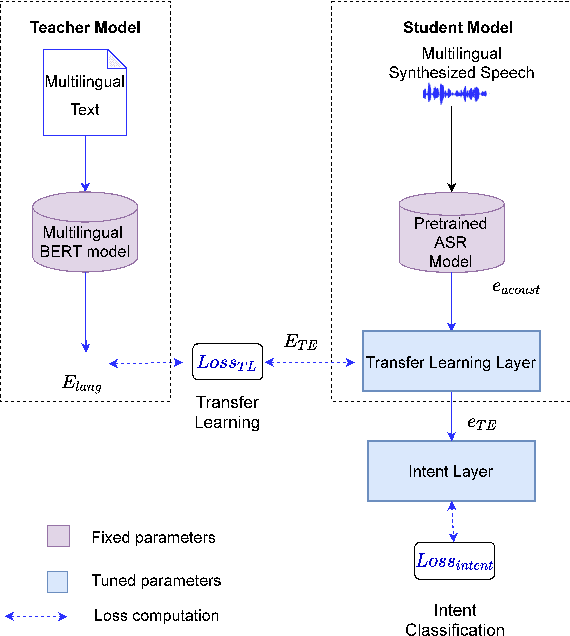
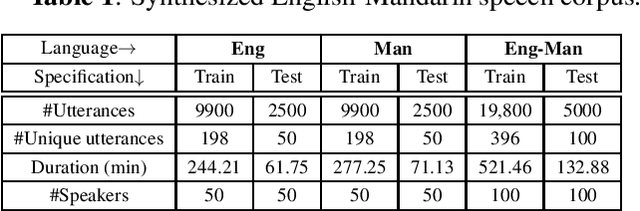
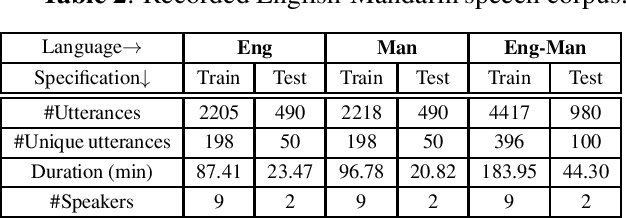
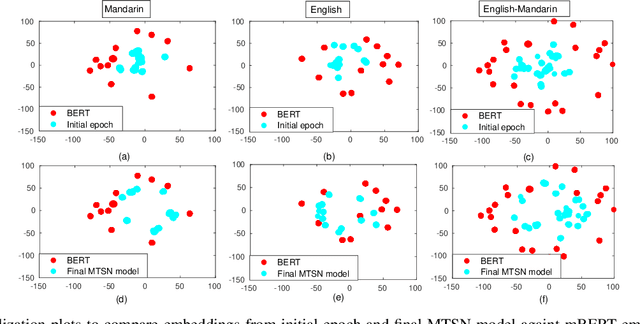
End-to-end speech-to-intent classification has shown its advantage in harvesting information from both text and speech. In this paper, we study a technique to develop such an end-to-end system that supports multiple languages. To overcome the scarcity of multi-lingual speech corpus, we exploit knowledge from a pre-trained multi-lingual natural language processing model. Multi-lingual bidirectional encoder representations from transformers (mBERT) models are trained on multiple languages and hence expected to perform well in the multi-lingual scenario. In this work, we employ a teacher-student learning approach to sufficiently extract information from an mBERT model to train a multi-lingual speech model. In particular, we use synthesized speech generated from an English-Mandarin text corpus for analysis and training of a multi-lingual intent classification model. We also demonstrate that the teacher-student learning approach obtains an improved performance (91.02%) over the traditional end-to-end (89.40%) intent classification approach in a practical multi-lingual scenario.