 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Teacher-Student Learning Approach for Multi-lingual Speech-to-Intent Classification
Paper and Code
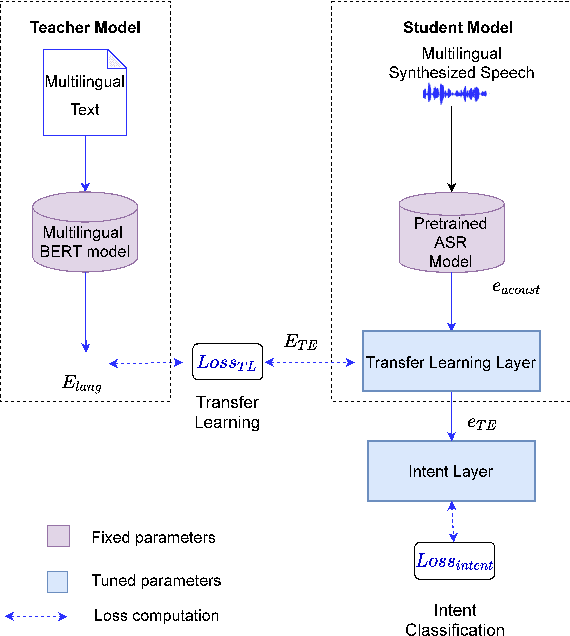
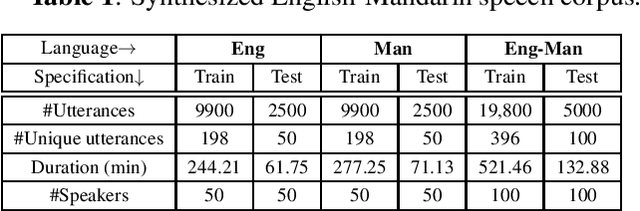
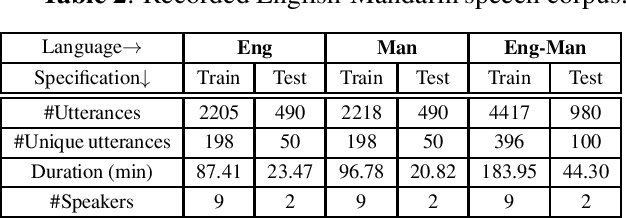
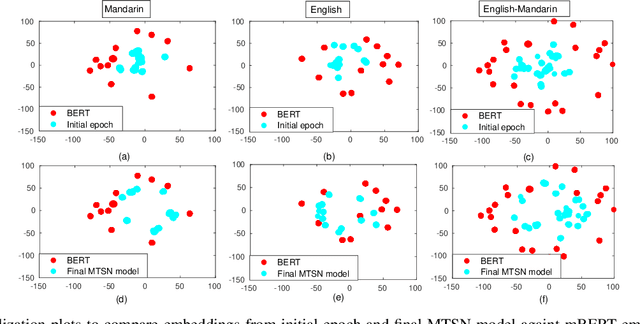
End-to-end speech-to-intent classification has shown its advantage in harvesting information from both text and speech. In this paper, we study a technique to develop such an end-to-end system that supports multiple languages. To overcome the scarcity of multi-lingual speech corpus, we exploit knowledge from a pre-trained multi-lingual natural language processing model. Multi-lingual bidirectional encoder representations from transformers (mBERT) models are trained on multiple languages and hence expected to perform well in the multi-lingual scenario. In this work, we employ a teacher-student learning approach to sufficiently extract information from an mBERT model to train a multi-lingual speech model. In particular, we use synthesized speech generated from an English-Mandarin text corpus for analysis and training of a multi-lingual intent classification model. We also demonstrate that the teacher-student learning approach obtains an improved performance (91.02%) over the traditional end-to-end (89.40%) intent classification approach in a practical multi-lingual scenario.