 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Pre-trained Language Models Better Continual Few-Shot Relation Extractors
Paper and Code
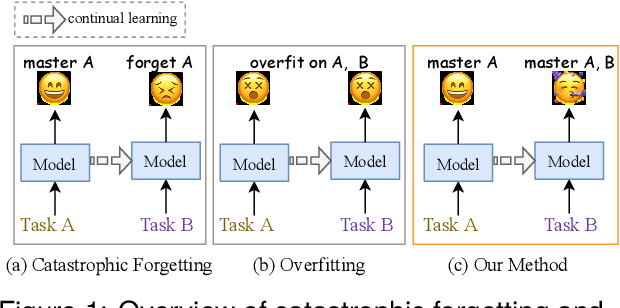
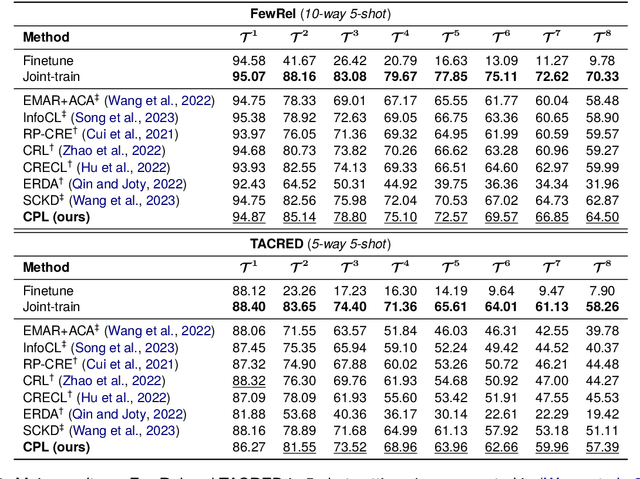


Continual Few-shot Relation Extraction (CFRE) is a practical problem that requires the model to continuously learn novel relations while avoiding forgetting old ones with few labeled training data. The primary challenges are catastrophic forgetting and overfitting. This paper harnesses prompt learning to explore the implicit capabilities of pre-trained language models to address the above two challenges, thereby making language models better continual few-shot relation extractors. Specifically, we propose a Contrastive Prompt Learning framework, which designs prompt representation to acquire more generalized knowledge that can be easily adapted to old and new categories, and margin-based contrastive learning to focus more on hard samples, therefore alleviating catastrophic forgetting and overfitting issues. To further remedy overfitting in low-resource scenarios, we introduce an effective memory augmentation strategy that employs well-crafted prompts to guide ChatGPT in generating diverse samples. Extensive experiments demonstrate that our method outperforms state-of-the-art methods by a large margin and significantly mitigates catastrophic forgetting and overfitting in low-resource scenarios.