 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Renaissance of Expert Systems: Optical Recognition of Printed Chinese Jianpu Musical Scores with Lyrics
Dec 15, 2025Large-scale optical music recognition (OMR) research has focused mainly on Western staff notation, leaving Chinese Jianpu (numbered notation) and its rich lyric resources underexplored. We present a modular expert-system pipeline that converts printed Jianpu scores with lyrics into machine-readable MusicXML and MIDI, without requiring massive annotated training data. Our approach adopts a top-down expert-system design, leveraging traditional computer-vision techniques (e.g., phrase correlation, skeleton analysis) to capitalize on prior knowledge, while integrating unsupervised deep-learning modules for image feature embeddings. This hybrid strategy strikes a balance between interpretability and accuracy. Evaluated on The Anthology of Chinese Folk Songs, our system massively digitizes (i) a melody-only collection of more than 5,000 songs (> 300,000 notes) and (ii) a curated subset with lyrics comprising over 1,400 songs (> 100,000 notes). The system achieves high-precision recognition on both melody (note-wise F1 = 0.951) and aligned lyrics (character-wise F1 = 0.931).
Marabou 2.0: A Versatile Formal Analyzer of Neural Networks
Jan 25, 2024
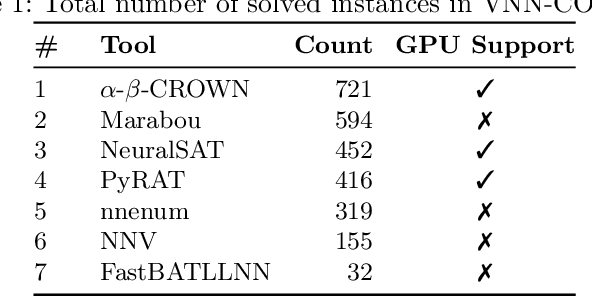

This paper serves as a comprehensive system description of version 2.0 of the Marabou framework for formal analysis of neural networks. We discuss the tool's architectural design and highlight the major features and components introduced since its initial release.
Towards Efficient Verification of Quantized Neural Networks
Dec 27, 2023



Quantization replaces floating point arithmetic with integer arithmetic in deep neural network models, providing more efficient on-device inference with less power and memory. In this work, we propose a framework for formally verifying properties of quantized neural networks. Our baseline technique is based on integer linear programming which guarantees both soundness and completeness. We then show how efficiency can be improved by utilizing gradient-based heuristic search methods and also bound-propagation techniques. We evaluate our approach on perception networks quantized with PyTorch. Our results show that we can verify quantized networks with better scalability and efficiency than the previous state of the art.
A Prompting-based Approach for Adversarial Example Generation and Robustness Enhancement
Mar 21, 2022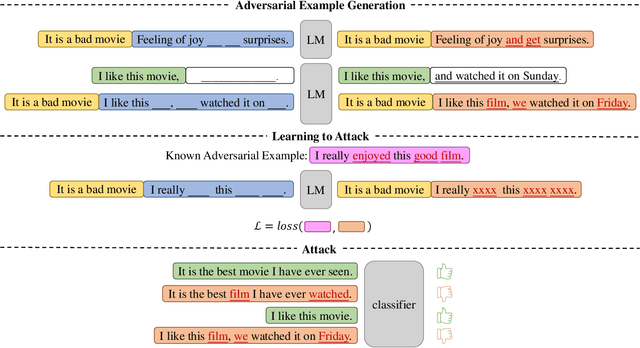



Recent years have seen the wide application of NLP models in crucial areas such as finance, medical treatment, and news media, raising concerns of the model robustness and vulnerabilities. In this paper, we propose a novel prompt-based adversarial attack to compromise NLP models and robustness enhancement technique. We first construct malicious prompts for each instance and generate adversarial examples via mask-and-filling under the effect of a malicious purpose. Our attack technique targets the inherent vulnerabilities of NLP models, allowing us to generate samples even without interacting with the victim NLP model, as long as it is based on pre-trained language models (PLMs). Furthermore, we design a prompt-based adversarial training method to improve the robustness of PLMs. As our training method does not actually generate adversarial samples, it can be applied to large-scale training sets efficiently. The experimental results show that our attack method can achieve a high attack success rate with more diverse, fluent and natural adversarial examples. In addition, our robustness enhancement method can significantly improve the robustness of models to resist adversarial attacks. Our work indicates that prompting paradigm has great potential in probing some fundamental flaws of PLMs and fine-tuning them for downstream tasks.
Quantifying Robustness to Adversarial Word Substitutions
Jan 11, 2022
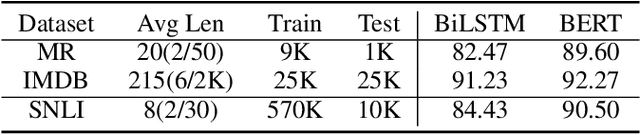
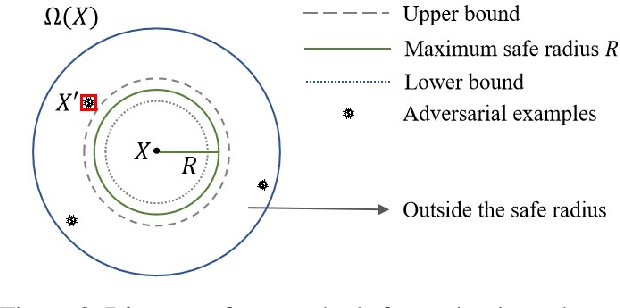

Deep-learning-based NLP models are found to be vulnerable to word substitution perturbations. Before they are widely adopted, the fundamental issues of robustness need to be addressed. Along this line, we propose a formal framework to evaluate word-level robustness. First, to study safe regions for a model, we introduce robustness radius which is the boundary where the model can resist any perturbation. As calculating the maximum robustness radius is computationally hard, we estimate its upper and lower bound. We repurpose attack methods as ways of seeking upper bound and design a pseudo-dynamic programming algorithm for a tighter upper bound. Then verification method is utilized for a lower bound. Further, for evaluating the robustness of regions outside a safe radius, we reexamine robustness from another view: quantification. A robustness metric with a rigorous statistical guarantee is introduced to measure the quantification of adversarial examples, which indicates the model's susceptibility to perturbations outside the safe radius. The metric helps us figure out why state-of-the-art models like BERT can be easily fooled by a few word substitutions, but generalize well in the presence of real-world noises.
Can Graph Neural Networks Learn to Solve MaxSAT Problem?
Nov 15, 2021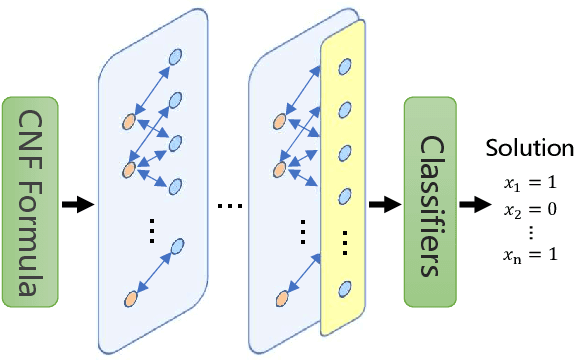
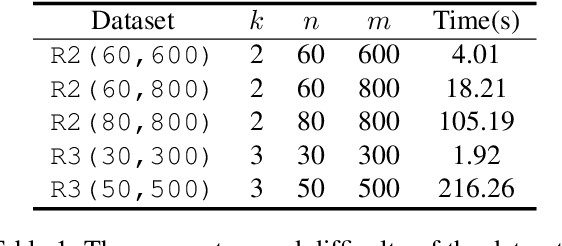
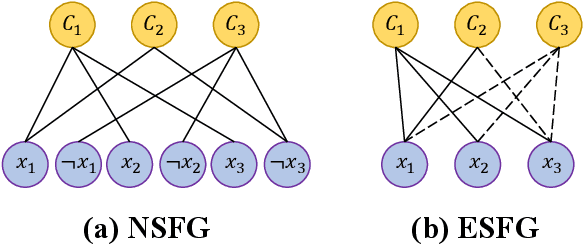

With the rapid development of deep learning techniques, various recent work has tried to apply graph neural networks (GNNs) to solve NP-hard problems such as Boolean Satisfiability (SAT), which shows the potential in bridging the gap between machine learning and symbolic reasoning. However, the quality of solutions predicted by GNNs has not been well investigated in the literature. In this paper, we study the capability of GNNs in learning to solve Maximum Satisfiability (MaxSAT) problem, both from theoretical and practical perspectives. We build two kinds of GNN models to learn the solution of MaxSAT instances from benchmarks, and show that GNNs have attractive potential to solve MaxSAT problem through experimental evaluation. We also present a theoretical explanation of the effect that GNNs can learn to solve MaxSAT problem to some extent for the first time, based on the algorithmic alignment theory.
ε-weakened Robustness of Deep Neural Networks
Oct 29, 2021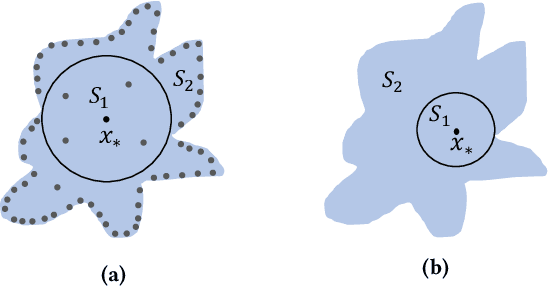

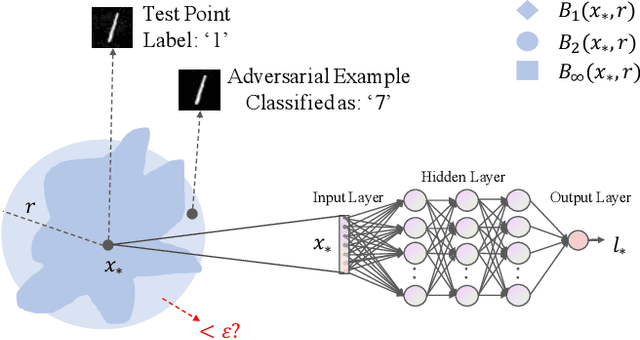
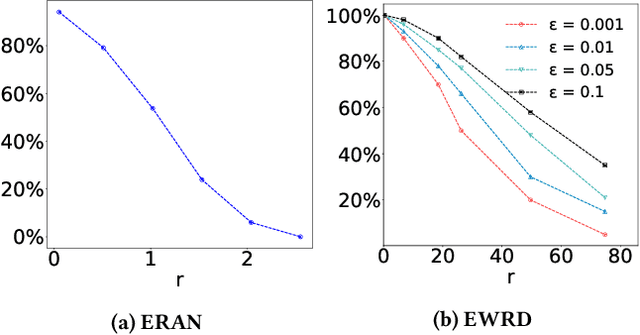
This paper introduces a notation of $\varepsilon$-weakened robustness for analyzing the reliability and stability of deep neural networks (DNNs). Unlike the conventional robustness, which focuses on the "perfect" safe region in the absence of adversarial examples, $\varepsilon$-weakened robustness focuses on the region where the proportion of adversarial examples is bounded by user-specified $\varepsilon$. Smaller $\varepsilon$ means a smaller chance of failure. Under such robustness definition, we can give conclusive results for the regions where conventional robustness ignores. We prove that the $\varepsilon$-weakened robustness decision problem is PP-complete and give a statistical decision algorithm with user-controllable error bound. Furthermore, we derive an algorithm to find the maximum $\varepsilon$-weakened robustness radius. The time complexity of our algorithms is polynomial in the dimension and size of the network. So, they are scalable to large real-world networks. Besides, We also show its potential application in analyzing quality issues.
Securing a UAV Using Individual Characteristics From an EEG Signal
Apr 15, 2017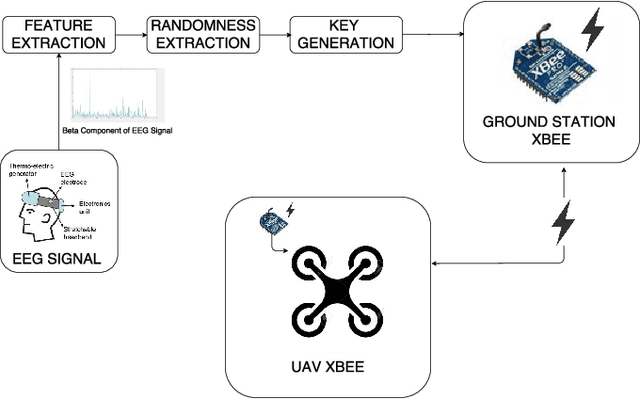

Unmanned aerial vehicles (UAVs) have gained much attention in recent years for both commercial and military applications. The progress in this field has gained much popularity and the research has encompassed various fields of scientific domain. Cyber securing a UAV communication has been one of the active research field since the attack on Predator UAV video stream hijacking in 2009. Since UAVs rely heavily on on-board autopilot to function, it is important to develop an autopilot system that is robust to possible cyber attacks. In this work, we present a biometric system to encrypt the UAV communication by generating a key which is derived from Beta component of the EEG signal of a user. We have developed a safety mechanism that would be activated in case the communication of the UAV from the ground control station gets attacked. This system has been validated on a commercial UAV under malicious attack conditions during which we implement a procedure where the UAV return safely to a "home" position.