 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Prompting-based Approach for Adversarial Example Generation and Robustness Enhancement
Paper and Code
Mar 21, 2022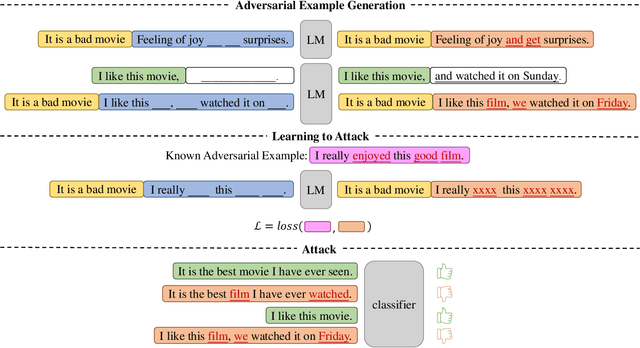



Recent years have seen the wide application of NLP models in crucial areas such as finance, medical treatment, and news media, raising concerns of the model robustness and vulnerabilities. In this paper, we propose a novel prompt-based adversarial attack to compromise NLP models and robustness enhancement technique. We first construct malicious prompts for each instance and generate adversarial examples via mask-and-filling under the effect of a malicious purpose. Our attack technique targets the inherent vulnerabilities of NLP models, allowing us to generate samples even without interacting with the victim NLP model, as long as it is based on pre-trained language models (PLMs). Furthermore, we design a prompt-based adversarial training method to improve the robustness of PLMs. As our training method does not actually generate adversarial samples, it can be applied to large-scale training sets efficiently. The experimental results show that our attack method can achieve a high attack success rate with more diverse, fluent and natural adversarial examples. In addition, our robustness enhancement method can significantly improve the robustness of models to resist adversarial attacks. Our work indicates that prompting paradigm has great potential in probing some fundamental flaws of PLMs and fine-tuning them for downstream tasks.