 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Robustness to Adversarial Word Substitutions
Jan 11, 2022
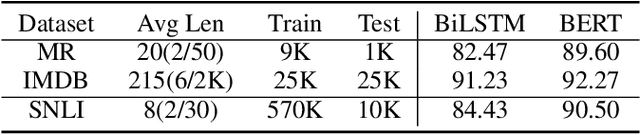
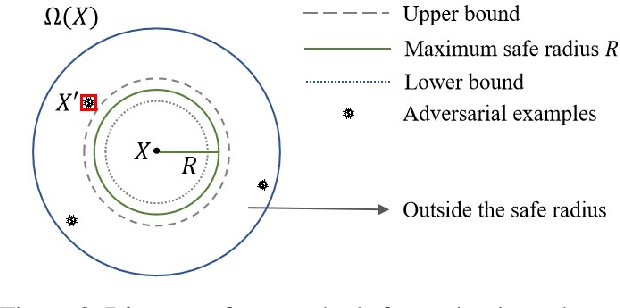

Deep-learning-based NLP models are found to be vulnerable to word substitution perturbations. Before they are widely adopted, the fundamental issues of robustness need to be addressed. Along this line, we propose a formal framework to evaluate word-level robustness. First, to study safe regions for a model, we introduce robustness radius which is the boundary where the model can resist any perturbation. As calculating the maximum robustness radius is computationally hard, we estimate its upper and lower bound. We repurpose attack methods as ways of seeking upper bound and design a pseudo-dynamic programming algorithm for a tighter upper bound. Then verification method is utilized for a lower bound. Further, for evaluating the robustness of regions outside a safe radius, we reexamine robustness from another view: quantification. A robustness metric with a rigorous statistical guarantee is introduced to measure the quantification of adversarial examples, which indicates the model's susceptibility to perturbations outside the safe radius. The metric helps us figure out why state-of-the-art models like BERT can be easily fooled by a few word substitutions, but generalize well in the presence of real-world noises.