 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric learning of covariate-based Markov jump processes using RKHS techniques
May 06, 2025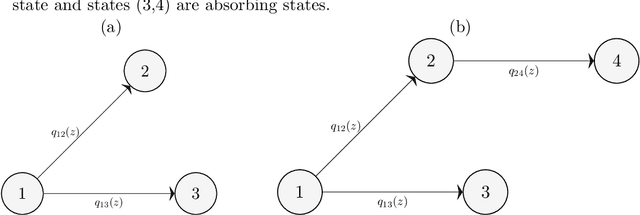



We propose a novel nonparametric approach for linking covariates to Continuous Time Markov Chains (CTMCs) using the mathematical framework of Reproducing Kernel Hilbert Spaces (RKHS). CTMCs provide a robust framework for modeling transitions across clinical or behavioral states, but traditional multistate models often rely on linear relationships. In contrast, we use a generalized Representer Theorem to enable tractable inference in functional space. For the Frequentist version, we apply normed square penalties, while for the Bayesian version, we explore sparsity inducing spike and slab priors. Due to the computational challenges posed by high-dimensional spaces, we successfully adapt the Expectation Maximization Variable Selection (EMVS) algorithm to efficiently identify the posterior mode. We demonstrate the effectiveness of our method through extensive simulation studies and an application to follicular cell lymphoma data. Our performance metrics include the normalized difference between estimated and true nonlinear transition functions, as well as the difference in the probability of getting absorbed in one the final states, capturing the ability of our approach to predict long-term behaviors.
Infinite-dimensional optimization and Bayesian nonparametric learning of stochastic differential equations
May 30, 2022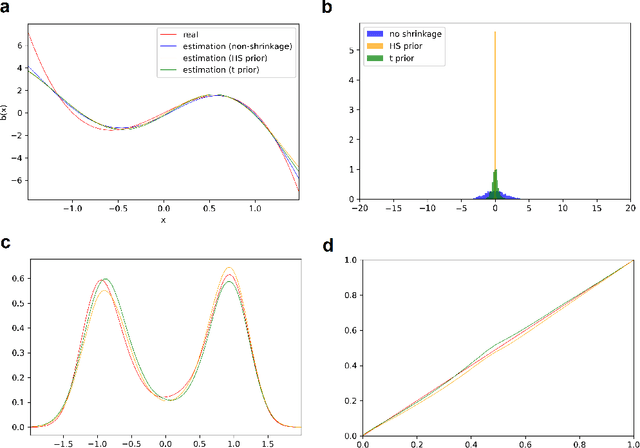


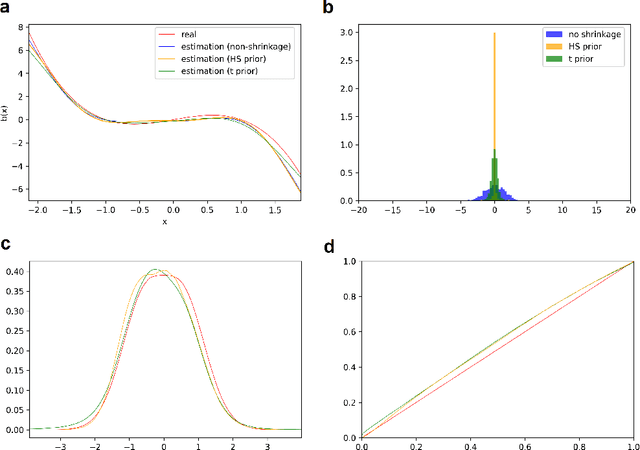
The paper has two major themes. The first part of the paper establishes certain general results for infinite-dimensional optimization problems on Hilbert spaces. These results cover the classical representer theorem and many of its variants as special cases and offer a wider scope of applications. The second part of the paper then develops a systematic approach for learning the drift function of a stochastic differential equation by integrating the results of the first part with Bayesian hierarchical framework. Importantly, our Baysian approach incorporates low-cost sparse learning through proper use of shrinkage priors while allowing proper quantification of uncertainty through posterior distributions. Several examples at the end illustrate the accuracy of our learning scheme.