 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Strategies for Security Games with General Defending Requirements
Apr 26, 2022

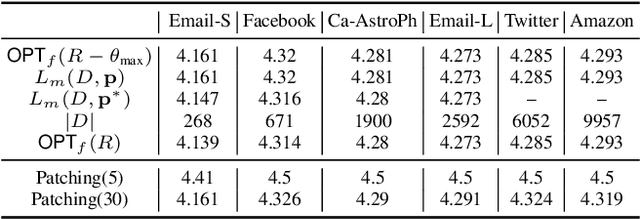

The Stackelberg security game is played between a defender and an attacker, where the defender needs to allocate a limited amount of resources to multiple targets in order to minimize the loss due to adversarial attack by the attacker. While allowing targets to have different values, classic settings often assume uniform requirements to defend the targets. This enables existing results that study mixed strategies (randomized allocation algorithms) to adopt a compact representation of the mixed strategies. In this work, we initiate the study of mixed strategies for the security games in which the targets can have different defending requirements. In contrast to the case of uniform defending requirement, for which an optimal mixed strategy can be computed efficiently, we show that computing the optimal mixed strategy is NP-hard for the general defending requirements setting. However, we show that strong upper and lower bounds for the optimal mixed strategy defending result can be derived. We propose an efficient close-to-optimal Patching algorithm that computes mixed strategies that use only few pure strategies. We also study the setting when the game is played on a network and resource sharing is enabled between neighboring targets. Our experimental results demonstrate the effectiveness of our algorithm in several large real-world datasets.
Preserving Dynamic Attention for Long-Term Spatial-Temporal Prediction
Jun 16, 2020
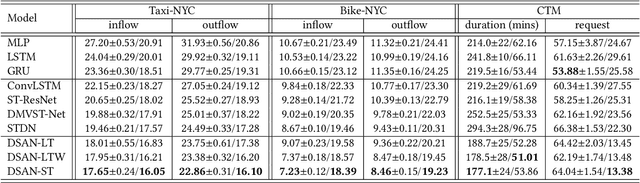

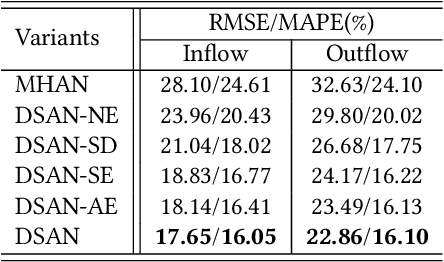
Effective long-term predictions have been increasingly demanded in urban-wise data mining systems. Many practical applications, such as accident prevention and resource pre-allocation, require an extended period for preparation. However, challenges come as long-term prediction is highly error-sensitive, which becomes more critical when predicting urban-wise phenomena with complicated and dynamic spatial-temporal correlation. Specifically, since the amount of valuable correlation is limited, enormous irrelevant features introduce noises that trigger increased prediction errors. Besides, after each time step, the errors can traverse through the correlations and reach the spatial-temporal positions in every future prediction, leading to significant error propagation. To address these issues, we propose a Dynamic Switch-Attention Network (DSAN) with a novel Multi-Space Attention (MSA) mechanism that measures the correlations between inputs and outputs explicitly. To filter out irrelevant noises and alleviate the error propagation, DSAN dynamically extracts valuable information by applying self-attention over the noisy input and bridges each output directly to the purified inputs via implementing a switch-attention mechanism. Through extensive experiments on two spatial-temporal prediction tasks, we demonstrate the superior advantage of DSAN in both short-term and long-term predictions.
Interpretable Crowd Flow Prediction with Spatial-Temporal Self-Attention
Feb 22, 2020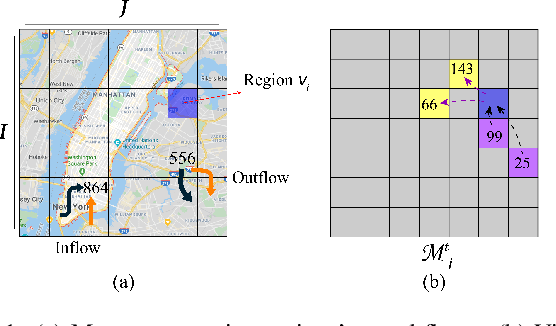
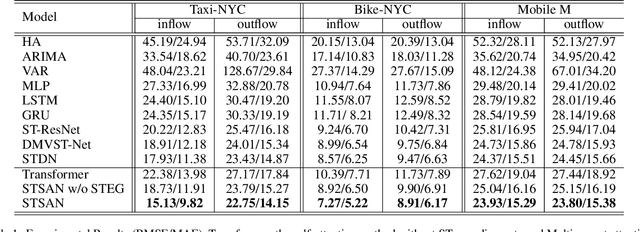
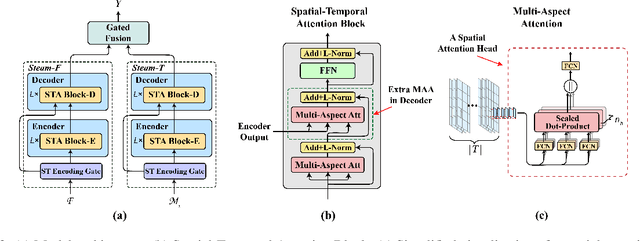
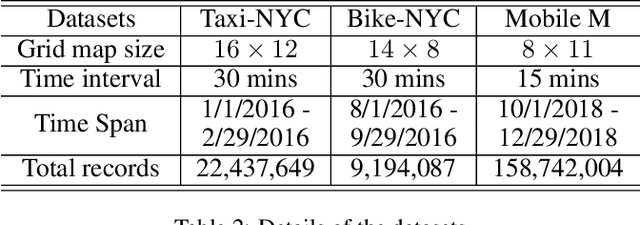
Crowd flow prediction has been increasingly investigated in intelligent urban computing field as a fundamental component of urban management system. The most challenging part of predicting crowd flow is to measure the complicated spatial-temporal dependencies. A prevalent solution employed in current methods is to divide and conquer the spatial and temporal information by various architectures (e.g., CNN/GCN, LSTM). However, this strategy has two disadvantages: (1) the sophisticated dependencies are also divided and therefore partially isolated; (2) the spatial-temporal features are transformed into latent representations when passing through different architectures, making it hard to interpret the predicted crowd flow. To address these issues, we propose a Spatial-Temporal Self-Attention Network (STSAN) with an ST encoding gate that calculates the entire spatial-temporal representation with positional and time encodings and therefore avoids dividing the dependencies. Furthermore, we develop a Multi-aspect attention mechanism that applies scaled dot-product attention over spatial-temporal information and measures the attention weights that explicitly indicate the dependencies. Experimental results on traffic and mobile data demonstrate that the proposed method reduces inflow and outflow RMSE by 16% and 8% on the Taxi-NYC dataset compared to the SOTA baselines.
Spatial-Temporal Self-Attention Network for Flow Prediction
Dec 23, 2019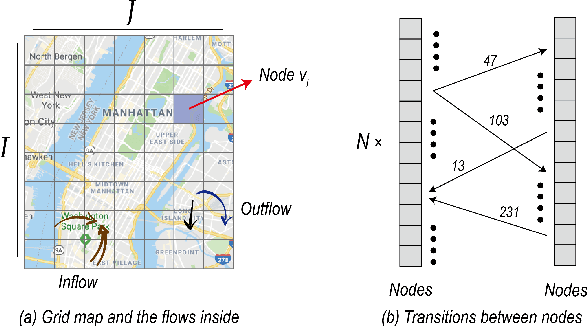
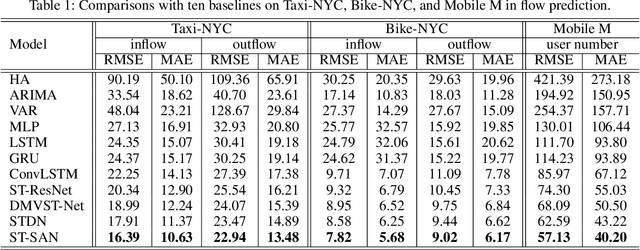
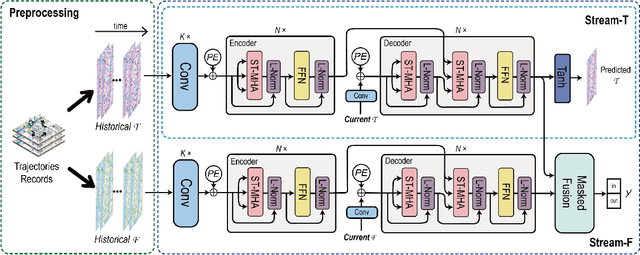
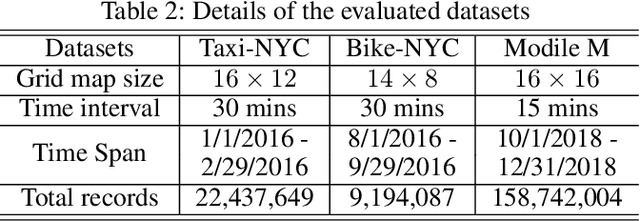
Flow prediction (e.g., crowd flow, traffic flow) with features of spatial-temporal is increasingly investigated in AI research field. It is very challenging due to the complicated spatial dependencies between different locations and dynamic temporal dependencies among different time intervals. Although measurements of both dependencies are employed, existing methods suffer from the following two problems. First, the temporal dependencies are measured either uniformly or bias against long-term dependencies, which overlooks the distinctive impacts of short-term and long-term temporal dependencies. Second, the existing methods capture spatial and temporal dependencies independently, which wrongly assumes that the correlations between these dependencies are weak and ignores the complicated mutual influences between them. To address these issues, we propose a Spatial-Temporal Self-Attention Network (ST-SAN). As the path-length of attending long-term dependency is shorter in the self-attention mechanism, the vanishing of long-term temporal dependencies is prevented. In addition, since our model relies solely on attention mechanisms, the spatial and temporal dependencies can be simultaneously measured. Experimental results on real-world data demonstrate that, in comparison with state-of-the-art methods, our model reduces the root mean square errors by 9% in inflow prediction and 4% in outflow prediction on Taxi-NYC data, which is very significant compared to the previous improvement.