 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Model Acceleration and Optimization Strategies for Real-Time Recommendation Systems
Jun 13, 2025With the rapid growth of Internet services, recommendation systems play a central role in delivering personalized content. Faced with massive user requests and complex model architectures, the key challenge for real-time recommendation systems is how to reduce inference latency and increase system throughput without sacrificing recommendation quality. This paper addresses the high computational cost and resource bottlenecks of deep learning models in real-time settings by proposing a combined set of modeling- and system-level acceleration and optimization strategies. At the model level, we dramatically reduce parameter counts and compute requirements through lightweight network design, structured pruning, and weight quantization. At the system level, we integrate multiple heterogeneous compute platforms and high-performance inference libraries, and we design elastic inference scheduling and load-balancing mechanisms based on real-time load characteristics. Experiments show that, while maintaining the original recommendation accuracy, our methods cut latency to less than 30% of the baseline and more than double system throughput, offering a practical solution for deploying large-scale online recommendation services.
Generating Multimodal Images with GAN: Integrating Text, Image, and Style
Jan 04, 2025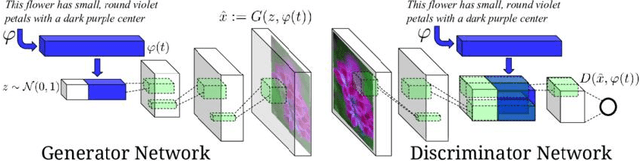
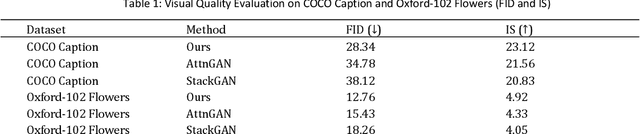
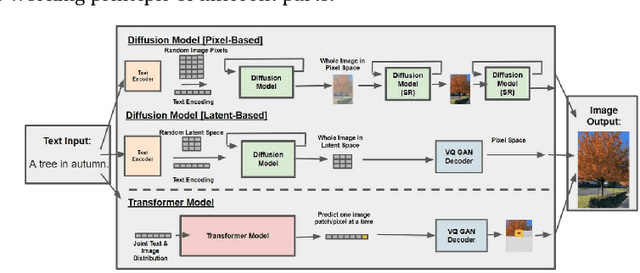

In the field of computer vision, multimodal image generation has become a research hotspot, especially the task of integrating text, image, and style. In this study, we propose a multimodal image generation method based on Generative Adversarial Networks (GAN), capable of effectively combining text descriptions, reference images, and style information to generate images that meet multimodal requirements. This method involves the design of a text encoder, an image feature extractor, and a style integration module, ensuring that the generated images maintain high quality in terms of visual content and style consistency. We also introduce multiple loss functions, including adversarial loss, text-image consistency loss, and style matching loss, to optimize the generation process. Experimental results show that our method produces images with high clarity and consistency across multiple public datasets, demonstrating significant performance improvements compared to existing methods. The outcomes of this study provide new insights into multimodal image generation and present broad application prospects.