 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssistQ: Affordance-centric Question-driven Task Completion for Egocentric Assistant
Mar 08, 2022
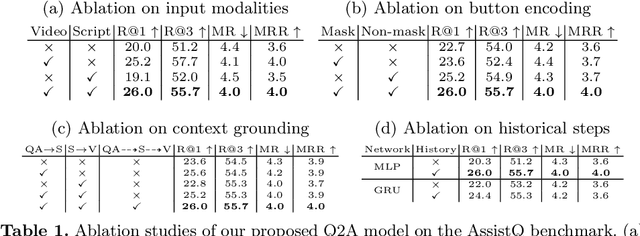
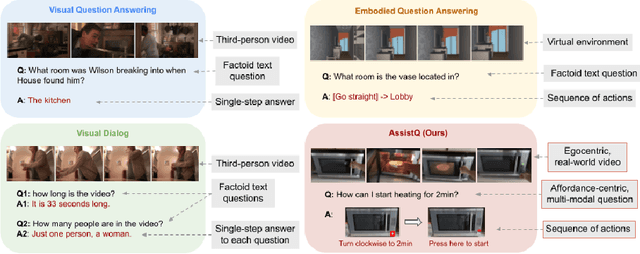

A long-standing goal of intelligent assistants such as AR glasses/robots has been to assist users in affordance-centric real-world scenarios, such as "how can I run the microwave for 1 minute?". However, there is still no clear task definition and suitable benchmarks. In this paper, we define a new task called Affordance-centric Question-driven Task Completion, where the AI assistant should learn from instructional videos and scripts to guide the user step-by-step. To support the task, we constructed AssistQ, a new dataset comprising 529 question-answer samples derived from 100 newly filmed first-person videos. Each question should be completed with multi-step guidances by inferring from visual details (e.g., buttons' position) and textural details (e.g., actions like press/turn). To address this unique task, we developed a Question-to-Actions (Q2A) model that significantly outperforms several baseline methods while still having large room for improvement. We expect our task and dataset to advance Egocentric AI Assistant's development. Our project page is available at: https://showlab.github.io/assistq