 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
F1: A Vision-Language-Action Model Bridging Understanding and Generation to Actions
Sep 09, 2025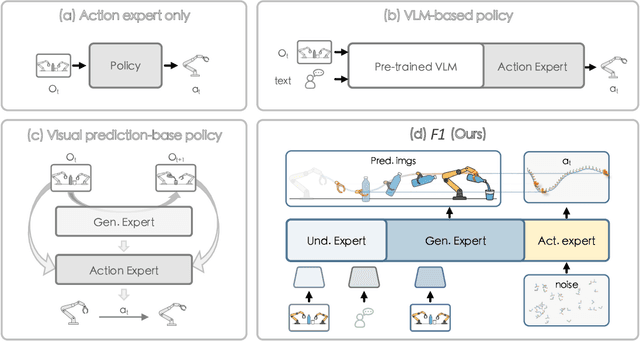

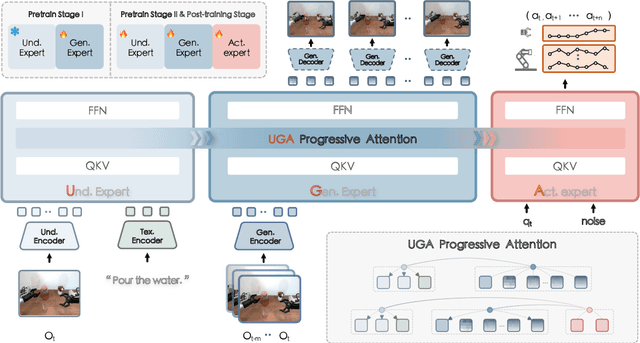

Executing language-conditioned tasks in dynamic visual environments remains a central challenge in embodied AI. Existing Vision-Language-Action (VLA) models predominantly adopt reactive state-to-action mappings, often leading to short-sighted behaviors and poor robustness in dynamic scenes. In this paper, we introduce F1, a pretrained VLA framework which integrates the visual foresight generation into decision-making pipeline. F1 adopts a Mixture-of-Transformer architecture with dedicated modules for perception, foresight generation, and control, thereby bridging understanding, generation, and actions. At its core, F1 employs a next-scale prediction mechanism to synthesize goal-conditioned visual foresight as explicit planning targets. By forecasting plausible future visual states, F1 reformulates action generation as a foresight-guided inverse dynamics problem, enabling actions that implicitly achieve visual goals. To endow F1 with robust and generalizable capabilities, we propose a three-stage training recipe on an extensive dataset comprising over 330k trajectories across 136 diverse tasks. This training scheme enhances modular reasoning and equips the model with transferable visual foresight, which is critical for complex and dynamic environments. Extensive evaluations on real-world tasks and simulation benchmarks demonstrate F1 consistently outperforms existing approaches, achieving substantial gains in both task success rate and generalization ability.
Deformable NeRF using Recursively Subdivided Tetrahedra
Oct 06, 2024



While neural radiance fields (NeRF) have shown promise in novel view synthesis, their implicit representation limits explicit control over object manipulation. Existing research has proposed the integration of explicit geometric proxies to enable deformation. However, these methods face two primary challenges: firstly, the time-consuming and computationally demanding tetrahedralization process; and secondly, handling complex or thin structures often leads to either excessive, storage-intensive tetrahedral meshes or poor-quality ones that impair deformation capabilities. To address these challenges, we propose DeformRF, a method that seamlessly integrates the manipulability of tetrahedral meshes with the high-quality rendering capabilities of feature grid representations. To avoid ill-shaped tetrahedra and tetrahedralization for each object, we propose a two-stage training strategy. Starting with an almost-regular tetrahedral grid, our model initially retains key tetrahedra surrounding the object and subsequently refines object details using finer-granularity mesh in the second stage. We also present the concept of recursively subdivided tetrahedra to create higher-resolution meshes implicitly. This enables multi-resolution encoding while only necessitating the storage of the coarse tetrahedral mesh generated in the first training stage. We conduct a comprehensive evaluation of our DeformRF on both synthetic and real-captured datasets. Both quantitative and qualitative results demonstrate the effectiveness of our method for novel view synthesis and deformation tasks. Project page: https://ustc3dv.github.io/DeformRF/