 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Semi-Supervised Learning with Contrastive Complementary Labeling
Dec 13, 2022



Semi-supervised learning (SSL) has achieved great success in leveraging a large amount of unlabeled data to learn a promising classifier. A popular approach is pseudo-labeling that generates pseudo labels only for those unlabeled data with high-confidence predictions. As for the low-confidence ones, existing methods often simply discard them because these unreliable pseudo labels may mislead the model. Nevertheless, we highlight that these data with low-confidence pseudo labels can be still beneficial to the training process. Specifically, although the class with the highest probability in the prediction is unreliable, we can assume that this sample is very unlikely to belong to the classes with the lowest probabilities. In this way, these data can be also very informative if we can effectively exploit these complementary labels, i.e., the classes that a sample does not belong to. Inspired by this, we propose a novel Contrastive Complementary Labeling (CCL) method that constructs a large number of reliable negative pairs based on the complementary labels and adopts contrastive learning to make use of all the unlabeled data. Extensive experiments demonstrate that CCL significantly improves the performance on top of existing methods. More critically, our CCL is particularly effective under the label-scarce settings. For example, we yield an improvement of 2.43% over FixMatch on CIFAR-10 only with 40 labeled data.
Improving Fine-tuning of Self-supervised Models with Contrastive Initialization
Jul 30, 2022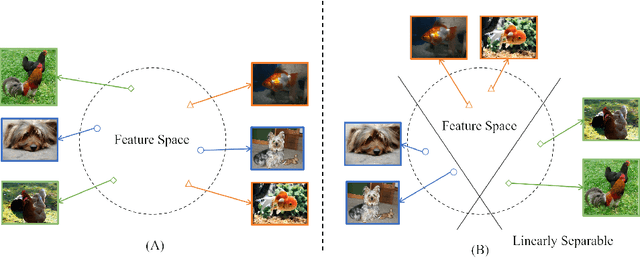
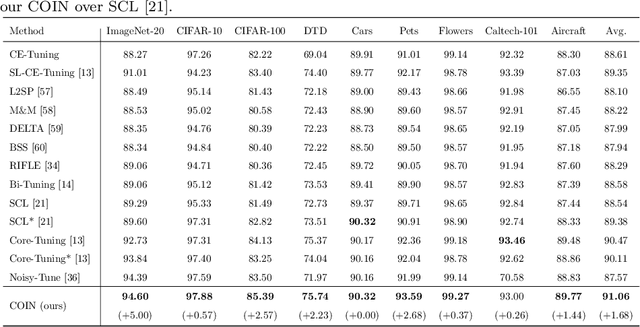
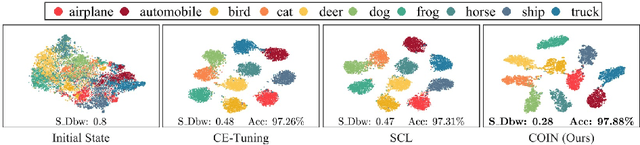
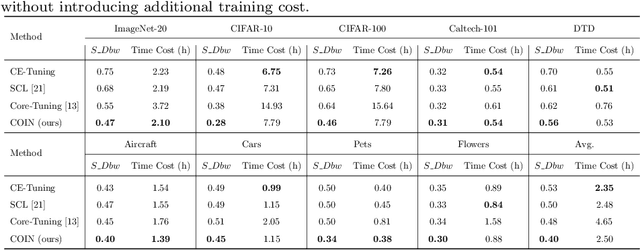
Self-supervised learning (SSL) has achieved remarkable performance in pretraining the models that can be further used in downstream tasks via fine-tuning. However, these self-supervised models may not capture meaningful semantic information since the images belonging to the same class are always regarded as negative pairs in the contrastive loss. Consequently, the images of the same class are often located far away from each other in learned feature space, which would inevitably hamper the fine-tuning process. To address this issue, we seek to provide a better initialization for the self-supervised models by enhancing the semantic information. To this end, we propose a Contrastive Initialization (COIN) method that breaks the standard fine-tuning pipeline by introducing an extra initialization stage before fine-tuning. Extensive experiments show that, with the enriched semantics, our COIN significantly outperforms existing methods without introducing extra training cost and sets new state-of-the-arts on multiple downstream tasks.