 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Fine-tuning of Self-supervised Models with Contrastive Initialization
Paper and Code
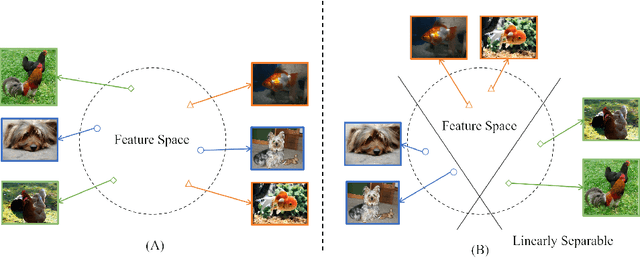
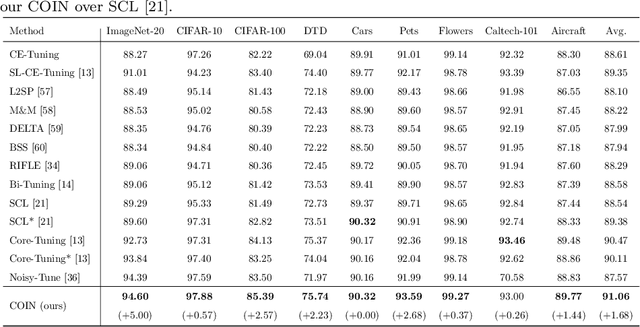
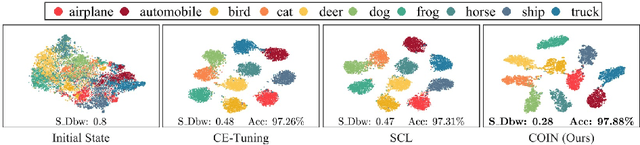
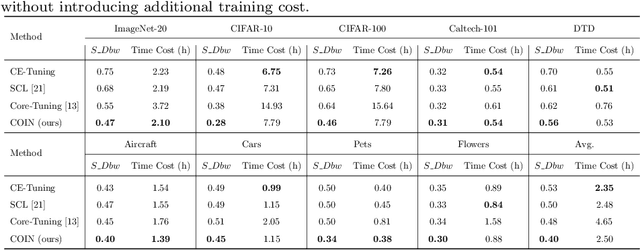
Self-supervised learning (SSL) has achieved remarkable performance in pretraining the models that can be further used in downstream tasks via fine-tuning. However, these self-supervised models may not capture meaningful semantic information since the images belonging to the same class are always regarded as negative pairs in the contrastive loss. Consequently, the images of the same class are often located far away from each other in learned feature space, which would inevitably hamper the fine-tuning process. To address this issue, we seek to provide a better initialization for the self-supervised models by enhancing the semantic information. To this end, we propose a Contrastive Initialization (COIN) method that breaks the standard fine-tuning pipeline by introducing an extra initialization stage before fine-tuning. Extensive experiments show that, with the enriched semantics, our COIN significantly outperforms existing methods without introducing extra training cost and sets new state-of-the-arts on multiple downstream tasks.