 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECCO: Evidence-Driven Causal Reasoning for Compiler Optimization
Jan 23, 2026Compiler auto-tuning faces a dichotomy between traditional black-box search methods, which lack semantic guidance, and recent Large Language Model (LLM) approaches, which often suffer from superficial pattern matching and causal opacity. In this paper, we introduce ECCO, a framework that bridges interpretable reasoning with combinatorial search. We first propose a reverse engineering methodology to construct a Chain-of-Thought dataset, explicitly mapping static code features to verifiable performance evidence. This enables the model to learn the causal logic governing optimization decisions rather than merely imitating sequences. Leveraging this interpretable prior, we design a collaborative inference mechanism where the LLM functions as a strategist, defining optimization intents that dynamically guide the mutation operations of a genetic algorithm. Experimental results on seven datasets demonstrate that ECCO significantly outperforms the LLVM opt -O3 baseline, achieving an average 24.44% reduction in cycles.
Gap Preserving Distillation by Building Bidirectional Mappings with A Dynamic Teacher
Oct 05, 2024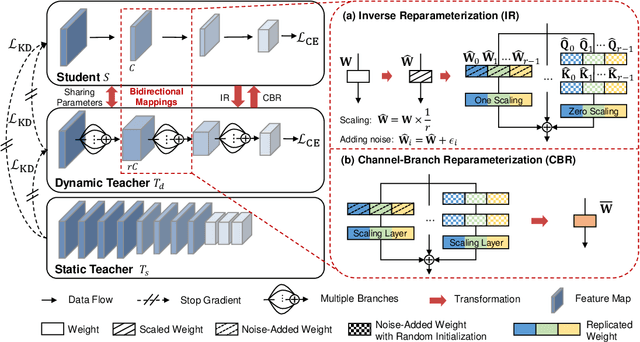
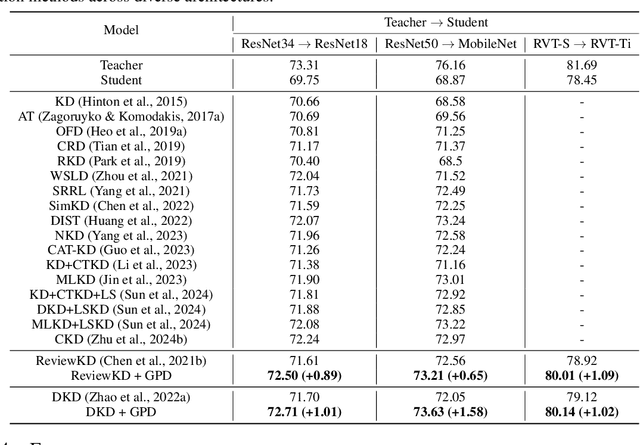
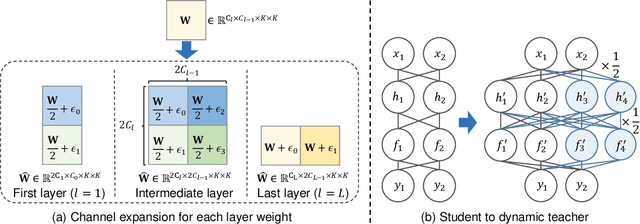

Knowledge distillation aims to transfer knowledge from a large teacher model to a compact student counterpart, often coming with a significant performance gap between them. We find that a too-large performance gap can hamper the training process, which is also verified in recent studies. To address this, we propose a Gap Preserving Distillation (GPD) method that trains an additional dynamic teacher model from scratch along with training the student to bridge this gap. In this way, it becomes possible to maintain a reasonable performance gap between teacher and student during the whole distillation process. To further strengthen distillation from the dynamic teacher to the student, we develop a hard strategy by enforcing them to share parameters and encouraging parameter inheritance. Besides hard strategy, we also build the soft bidirectional mappings between them which are built on an Inverse Reparameterization (IR) method and a Channel-Branch Reparameterization (CBR) strategy. We highlight that our IR is able to initialize a larger dynamic teacher with an arbitrary expansion ratio, while preserving exactly the same accuracy as the given student model. In this way, it guarantees that the dynamic teacher and student start from the same point and avoid a too large gap in early stage of training. As for our CBR, with parameter-sharing, it directly extracts an effective student model from the well-learned dynamic teacher without any post-training, making our method highly flexible for model deployment. In the experiments, GPD significantly outperforms existing distillation methods on top of both CNNs and transformers architectures, achieving up to 1.58% accuracy improvement. Interestingly, GPD also generalizes well to the scenarios without a pre-trained teacher, including training from scratch and fine-tuning, yielding a large improvement of 1.80% and 0.89% on ResNet18, respectively.
Enhanced Long-Tailed Recognition with Contrastive CutMix Augmentation
Jul 06, 2024Real-world data often follows a long-tailed distribution, where a few head classes occupy most of the data and a large number of tail classes only contain very limited samples. In practice, deep models often show poor generalization performance on tail classes due to the imbalanced distribution. To tackle this, data augmentation has become an effective way by synthesizing new samples for tail classes. Among them, one popular way is to use CutMix that explicitly mixups the images of tail classes and the others, while constructing the labels according to the ratio of areas cropped from two images. However, the area-based labels entirely ignore the inherent semantic information of the augmented samples, often leading to misleading training signals. To address this issue, we propose a Contrastive CutMix (ConCutMix) that constructs augmented samples with semantically consistent labels to boost the performance of long-tailed recognition. Specifically, we compute the similarities between samples in the semantic space learned by contrastive learning, and use them to rectify the area-based labels. Experiments show that our ConCutMix significantly improves the accuracy on tail classes as well as the overall performance. For example, based on ResNeXt-50, we improve the overall accuracy on ImageNet-LT by 3.0% thanks to the significant improvement of 3.3% on tail classes. We highlight that the improvement also generalizes well to other benchmarks and models. Our code and pretrained models are available at https://github.com/PanHaulin/ConCutMix.
Boosting Semi-Supervised Learning with Contrastive Complementary Labeling
Dec 13, 2022



Semi-supervised learning (SSL) has achieved great success in leveraging a large amount of unlabeled data to learn a promising classifier. A popular approach is pseudo-labeling that generates pseudo labels only for those unlabeled data with high-confidence predictions. As for the low-confidence ones, existing methods often simply discard them because these unreliable pseudo labels may mislead the model. Nevertheless, we highlight that these data with low-confidence pseudo labels can be still beneficial to the training process. Specifically, although the class with the highest probability in the prediction is unreliable, we can assume that this sample is very unlikely to belong to the classes with the lowest probabilities. In this way, these data can be also very informative if we can effectively exploit these complementary labels, i.e., the classes that a sample does not belong to. Inspired by this, we propose a novel Contrastive Complementary Labeling (CCL) method that constructs a large number of reliable negative pairs based on the complementary labels and adopts contrastive learning to make use of all the unlabeled data. Extensive experiments demonstrate that CCL significantly improves the performance on top of existing methods. More critically, our CCL is particularly effective under the label-scarce settings. For example, we yield an improvement of 2.43% over FixMatch on CIFAR-10 only with 40 labeled data.
Improving Fine-tuning of Self-supervised Models with Contrastive Initialization
Jul 30, 2022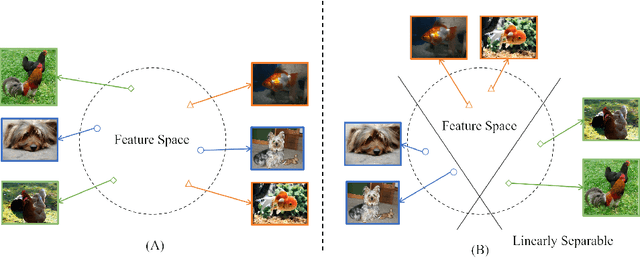
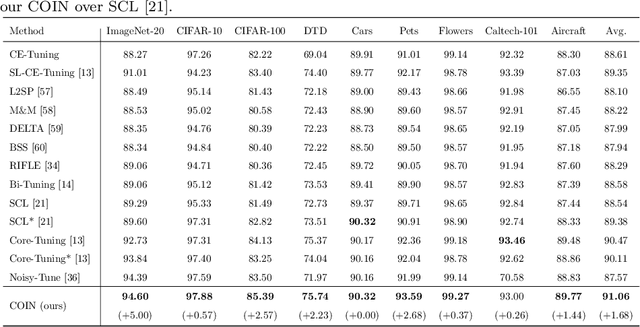
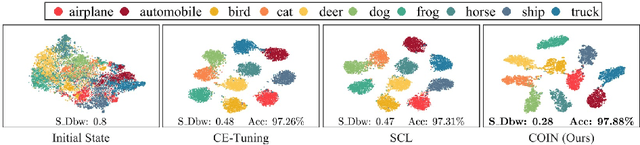
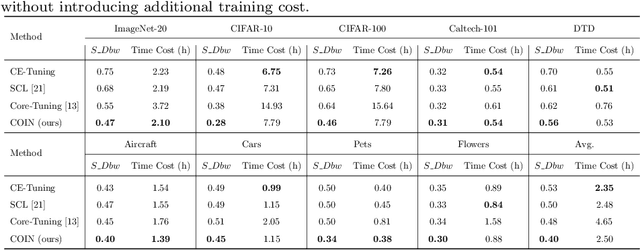
Self-supervised learning (SSL) has achieved remarkable performance in pretraining the models that can be further used in downstream tasks via fine-tuning. However, these self-supervised models may not capture meaningful semantic information since the images belonging to the same class are always regarded as negative pairs in the contrastive loss. Consequently, the images of the same class are often located far away from each other in learned feature space, which would inevitably hamper the fine-tuning process. To address this issue, we seek to provide a better initialization for the self-supervised models by enhancing the semantic information. To this end, we propose a Contrastive Initialization (COIN) method that breaks the standard fine-tuning pipeline by introducing an extra initialization stage before fine-tuning. Extensive experiments show that, with the enriched semantics, our COIN significantly outperforms existing methods without introducing extra training cost and sets new state-of-the-arts on multiple downstream tasks.
Unseen Object 6D Pose Estimation: A Benchmark and Baselines
Jun 23, 2022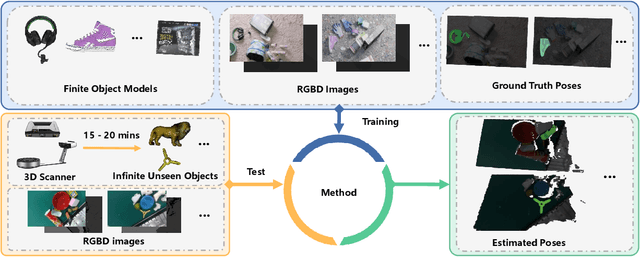
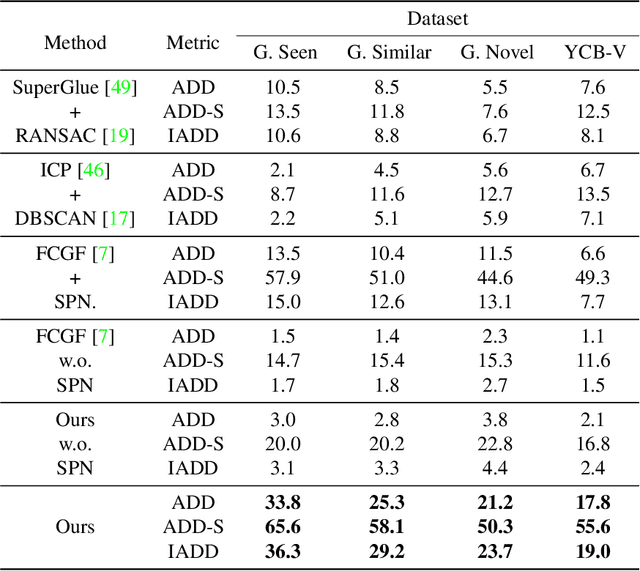

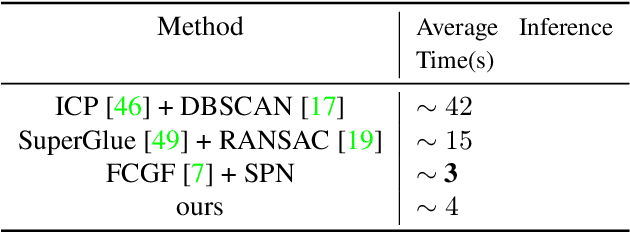
Estimating the 6D pose for unseen objects is in great demand for many real-world applications. However, current state-of-the-art pose estimation methods can only handle objects that are previously trained. In this paper, we propose a new task that enables and facilitates algorithms to estimate the 6D pose estimation of novel objects during testing. We collect a dataset with both real and synthetic images and up to 48 unseen objects in the test set. In the mean while, we propose a new metric named Infimum ADD (IADD) which is an invariant measurement for objects with different types of pose ambiguity. A two-stage baseline solution for this task is also provided. By training an end-to-end 3D correspondences network, our method finds corresponding points between an unseen object and a partial view RGBD image accurately and efficiently. It then calculates the 6D pose from the correspondences using an algorithm robust to object symmetry. Extensive experiments show that our method outperforms several intuitive baselines and thus verify its effectiveness. All the data, code and models will be made publicly available. Project page: www.graspnet.net/unseen6d