 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGap Preserving Distillation by Building Bidirectional Mappings with A Dynamic Teacher
Oct 05, 2024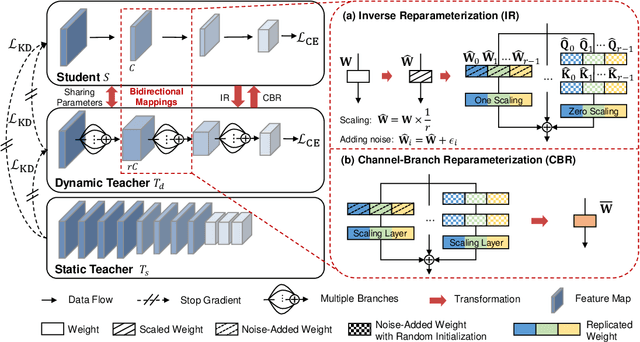
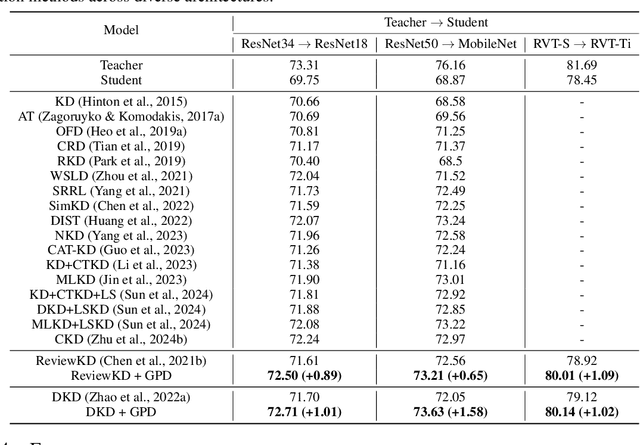
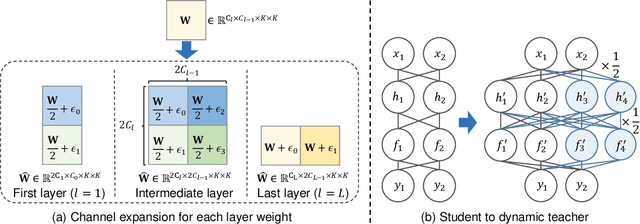

Knowledge distillation aims to transfer knowledge from a large teacher model to a compact student counterpart, often coming with a significant performance gap between them. We find that a too-large performance gap can hamper the training process, which is also verified in recent studies. To address this, we propose a Gap Preserving Distillation (GPD) method that trains an additional dynamic teacher model from scratch along with training the student to bridge this gap. In this way, it becomes possible to maintain a reasonable performance gap between teacher and student during the whole distillation process. To further strengthen distillation from the dynamic teacher to the student, we develop a hard strategy by enforcing them to share parameters and encouraging parameter inheritance. Besides hard strategy, we also build the soft bidirectional mappings between them which are built on an Inverse Reparameterization (IR) method and a Channel-Branch Reparameterization (CBR) strategy. We highlight that our IR is able to initialize a larger dynamic teacher with an arbitrary expansion ratio, while preserving exactly the same accuracy as the given student model. In this way, it guarantees that the dynamic teacher and student start from the same point and avoid a too large gap in early stage of training. As for our CBR, with parameter-sharing, it directly extracts an effective student model from the well-learned dynamic teacher without any post-training, making our method highly flexible for model deployment. In the experiments, GPD significantly outperforms existing distillation methods on top of both CNNs and transformers architectures, achieving up to 1.58% accuracy improvement. Interestingly, GPD also generalizes well to the scenarios without a pre-trained teacher, including training from scratch and fine-tuning, yielding a large improvement of 1.80% and 0.89% on ResNet18, respectively.