 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Code Generation to Improve Code Retrieval and Summarization via Dual Learning
Paper and Code
Feb 25, 2020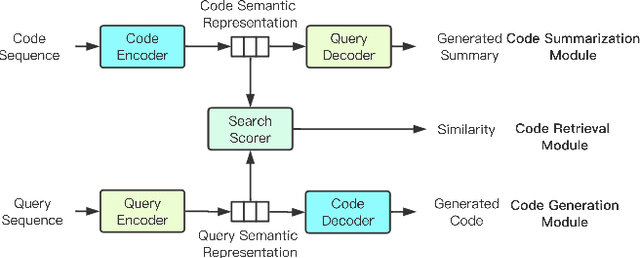
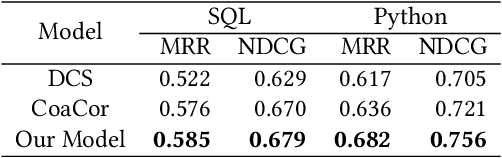
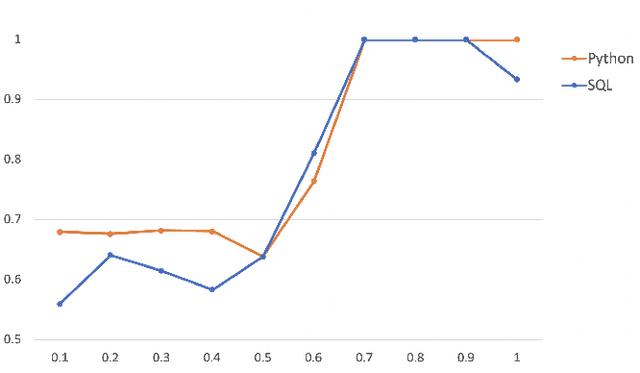
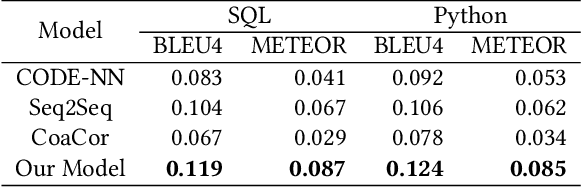
Code summarization generates brief natural language description given a source code snippet, while code retrieval fetches relevant source code given a natural language query. Since both tasks aim to model the association between natural language and programming language, recent studies have combined these two tasks to improve their performance. However, researchers have yet been able to effectively leverage the intrinsic connection between the two tasks as they train these tasks in a separate or pipeline manner, which means their performance can not be well balanced. In this paper, we propose a novel end-to-end model for the two tasks by introducing an additional code generation task. More specifically, we explicitly exploit the probabilistic correlation between code summarization and code generation with dual learning, and utilize the two encoders for code summarization and code generation to train the code retrieval task via multi-task learning. We have carried out extensive experiments on an existing dataset of SQL and Python, and results show that our model can significantly improve the results of the code retrieval task over the-state-of-art models, as well as achieve competitive performance in terms of BLEU score for the code summarization task.