 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabeling Comic Mischief Content in Online Videos with a Multimodal Hierarchical-Cross-Attention Model
Jun 12, 2024


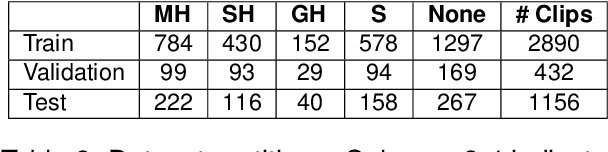
We address the challenge of detecting questionable content in online media, specifically the subcategory of comic mischief. This type of content combines elements such as violence, adult content, or sarcasm with humor, making it difficult to detect. Employing a multimodal approach is vital to capture the subtle details inherent in comic mischief content. To tackle this problem, we propose a novel end-to-end multimodal system for the task of comic mischief detection. As part of this contribution, we release a novel dataset for the targeted task consisting of three modalities: video, text (video captions and subtitles), and audio. We also design a HIerarchical Cross-attention model with CAPtions (HICCAP) to capture the intricate relationships among these modalities. The results show that the proposed approach makes a significant improvement over robust baselines and state-of-the-art models for comic mischief detection and its type classification. This emphasizes the potential of our system to empower users, to make informed decisions about the online content they choose to see. In addition, we conduct experiments on the UCF101, HMDB51, and XD-Violence datasets, comparing our model against other state-of-the-art approaches showcasing the outstanding performance of our proposed model in various scenarios.
Interpreting Themes from Educational Stories
Apr 08, 2024Reading comprehension continues to be a crucial research focus in the NLP community. Recent advances in Machine Reading Comprehension (MRC) have mostly centered on literal comprehension, referring to the surface-level understanding of content. In this work, we focus on the next level - interpretive comprehension, with a particular emphasis on inferring the themes of a narrative text. We introduce the first dataset specifically designed for interpretive comprehension of educational narratives, providing corresponding well-edited theme texts. The dataset spans a variety of genres and cultural origins and includes human-annotated theme keywords with varying levels of granularity. We further formulate NLP tasks under different abstractions of interpretive comprehension toward the main idea of a story. After conducting extensive experiments with state-of-the-art methods, we found the task to be both challenging and significant for NLP research. The dataset and source code have been made publicly available to the research community at https://github.com/RiTUAL-UH/EduStory.
Positive and Risky Message Assessment for Music Products
Sep 18, 2023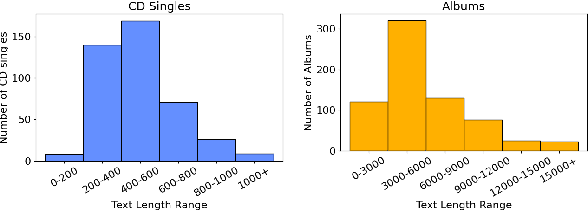


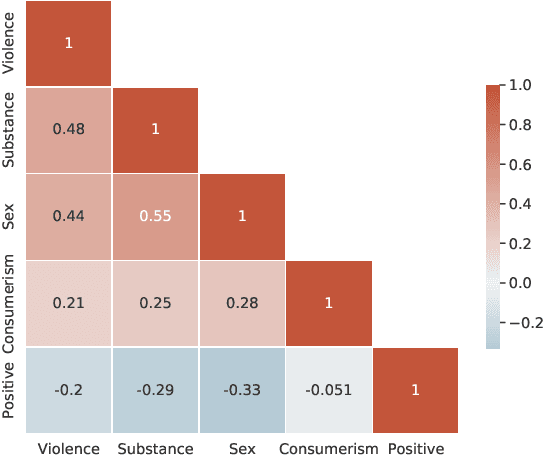
In this work, we propose a novel research problem: assessing positive and risky messages from music products. We first establish a benchmark for multi-angle multi-level music content assessment and then present an effective multi-task prediction model with ordinality-enforcement to solve this problem. Our result shows the proposed method not only significantly outperforms strong task-specific counterparts but can concurrently evaluate multiple aspects.
BagFormer: Better Cross-Modal Retrieval via bag-wise interaction
Dec 29, 2022



In the field of cross-modal retrieval, single encoder models tend to perform better than dual encoder models, but they suffer from high latency and low throughput. In this paper, we present a dual encoder model called BagFormer that utilizes a cross modal interaction mechanism to improve recall performance without sacrificing latency and throughput. BagFormer achieves this through the use of bag-wise interactions, which allow for the transformation of text to a more appropriate granularity and the incorporation of entity knowledge into the model. Our experiments demonstrate that BagFormer is able to achieve results comparable to state-of-the-art single encoder models in cross-modal retrieval tasks, while also offering efficient training and inference with 20.72 times lower latency and 25.74 times higher throughput.
From None to Severe: Predicting Severity in Movie Scripts
Oct 03, 2021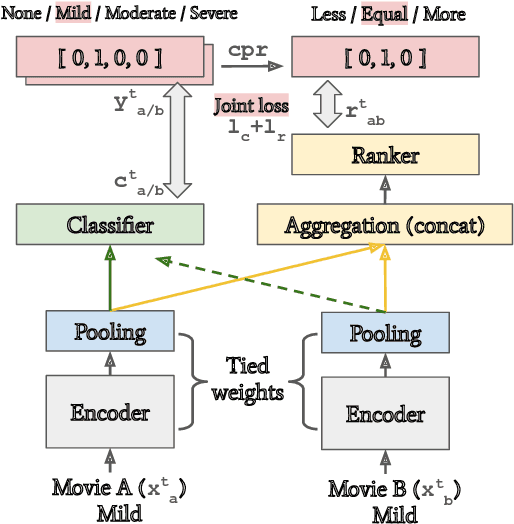
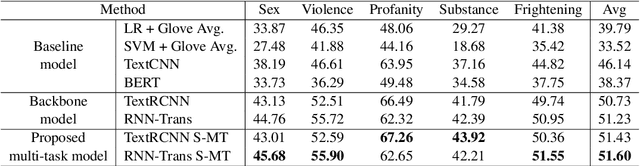
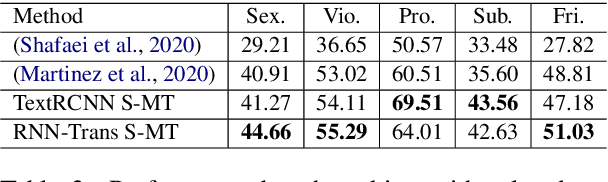
In this paper, we introduce the task of predicting severity of age-restricted aspects of movie content based solely on the dialogue script. We first investigate categorizing the ordinal severity of movies on 5 aspects: Sex, Violence, Profanity, Substance consumption, and Frightening scenes. The problem is handled using a siamese network-based multitask framework which concurrently improves the interpretability of the predictions. The experimental results show that our method outperforms the previous state-of-the-art model and provides useful information to interpret model predictions. The proposed dataset and source code are publicly available at our GitHub repository.
Birds of a Feather Flock Together: Satirical News Detection via Language Model Differentiation
Jul 04, 2020
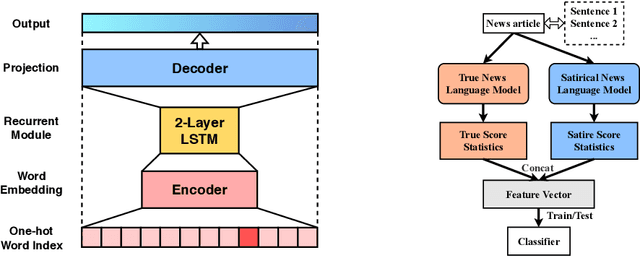
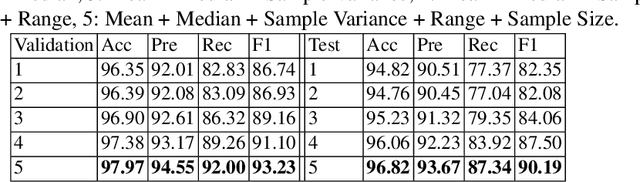
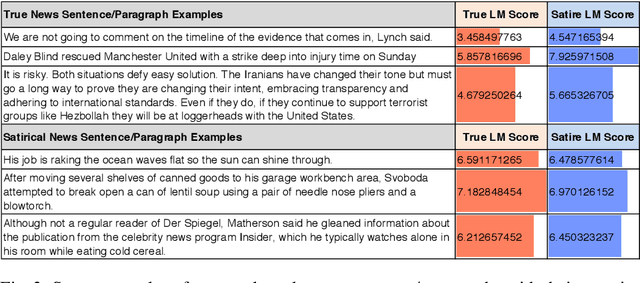
Satirical news is regularly shared in modern social media because it is entertaining with smartly embedded humor. However, it can be harmful to society because it can sometimes be mistaken as factual news, due to its deceptive character. We found that in satirical news, the lexical and pragmatical attributes of the context are the key factors in amusing the readers. In this work, we propose a method that differentiates the satirical news and true news. It takes advantage of satirical writing evidence by leveraging the difference between the prediction loss of two language models, one trained on true news and the other on satirical news, when given a new news article. We compute several statistical metrics of language model prediction loss as features, which are then used to conduct downstream classification. The proposed method is computationally effective because the language models capture the language usage differences between satirical news documents and traditional news documents, and are sensitive when applied to documents outside their domains.